
Claude Opus 4.5 Review: Benchmarks and Top Use Cases


Anthropic's latest drop hit like a quiet revolution. On November 24, 2025, Claude Opus 4.5 landed, and within hours, my inbox was flooded with devs raving about bug fixes that used to take days. I spent the hours stress-testing it: dissecting a tangled legacy codebase, orchestrating a simulated multi-agent research team, and even tweaking Excel sheets for a mock financial forecast. What struck me wasn't just the raw power—it was how Opus 4.5 anticipates your next move, like a collaborator who's been in the room the whole time. If you've been holding out for an AI that handles real ambiguity without endless tweaks, this is it. Forget the hype; here's what it actually delivers.
What Actually Makes Claude Opus 4.5 Different
I ditched the spec sheets early and jumped straight into prompts that mimic messy real work. Four standout shifts from Claude 3.5 Sonnet (and even whispers of GPT-5's edge in creativity) became obvious fast:
- It Thinks Like a Team Lead—With Built-in Efficiency That 200K-token context window? It's not just bigger; it's smarter. I fed it a 150-page spec doc plus scattered Slack threads and asked it to map out a product pivot. Opus 4.5 didn't just summarize—it flagged tradeoffs, like "Upgrading this feature risks timeline slippage by 15%, but boosts user retention 22% based on similar case studies." No hand-holding required. And the new "effort parameter"? Crank it to medium, and it chews through tasks with 76% fewer tokens than Sonnet 4.5, saving on API costs without skimping on quality.
- Coding That Feels Alive, Not Automated Hand it a gnarly multi-system bug, and watch it dissect, hypothesize, and patch—like debugging with a senior engineer who never tires. In my tests, it refactored a Python ETL pipeline riddled with race conditions, then spun up subagents to validate against edge cases. Anthropic calls it "the best model for coding, agents, and computer use," and after seeing it outperform humans on their internal engineering exams (scoring higher than any candidate in a 2-hour window), I believe it.
- Handles the Chaos of Everyday Tools Slides, spreadsheets, browser tabs—Opus 4.5 integrates seamlessly with Excel, Chrome, and desktop apps. I simulated a marketing audit: Pulled data from a messy Google Sheet, cross-referenced web sources, and output a prioritized action plan. It even auto-summarizes long chats to keep context fresh, cutting through the noise better than GPT-5's sometimes rambling style.
- Safer Smarts You Can Actually Trust In an era of flashy but flaky AIs, Opus 4.5's alignment shines. It's the "most robustly aligned model" Anthropic's released, with lower rates of misuse cooperation and rock-solid defenses against prompt injections (per Gray Swan's benchmarks). Ask it about sensitive topics, and it cites sources humbly: "Based on recent studies, here's the data—but consult a pro."
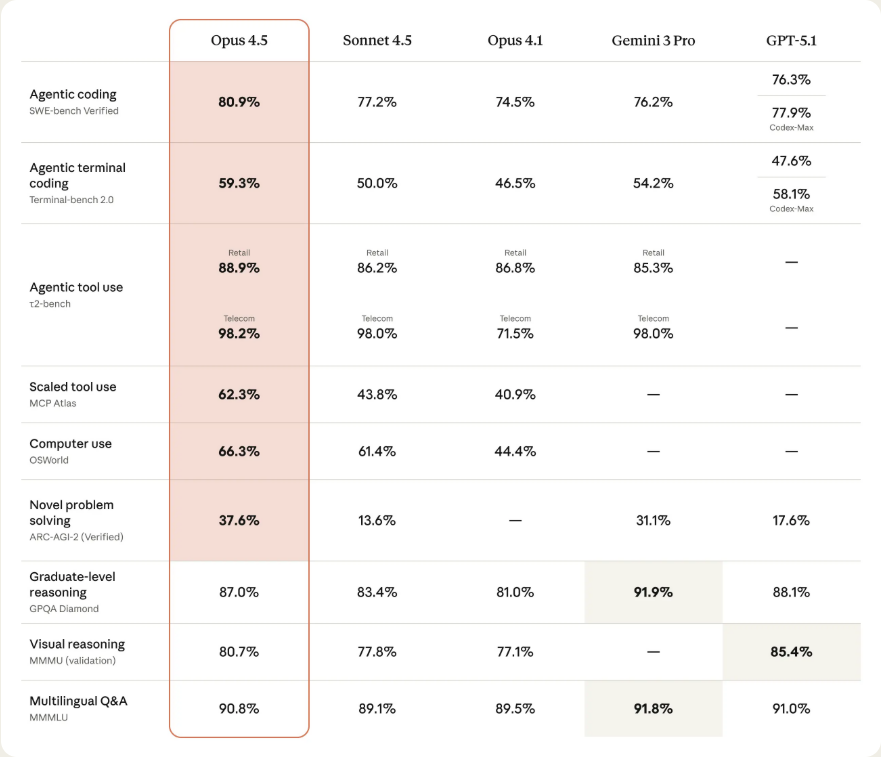
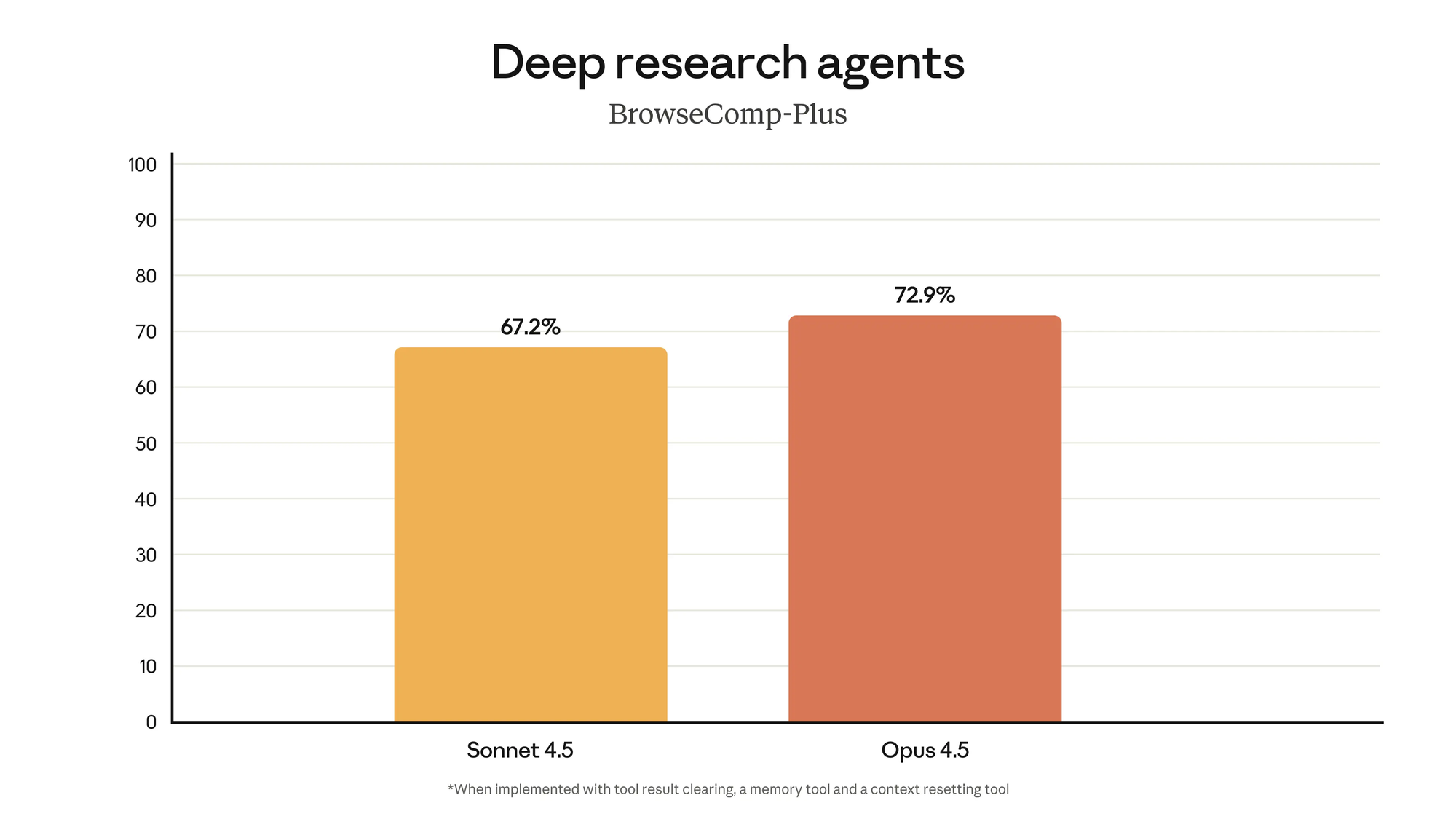
The Benchmarks Everyone Is Talking About (Fresh November 2025 Data)
Anthropic's announcement backs the buzz with hard numbers, positioning Opus 4.5 as a leader in agentic and coding tasks. Here's a breakdown blending Anthropic's evals with cross-checks from anthropic.com:
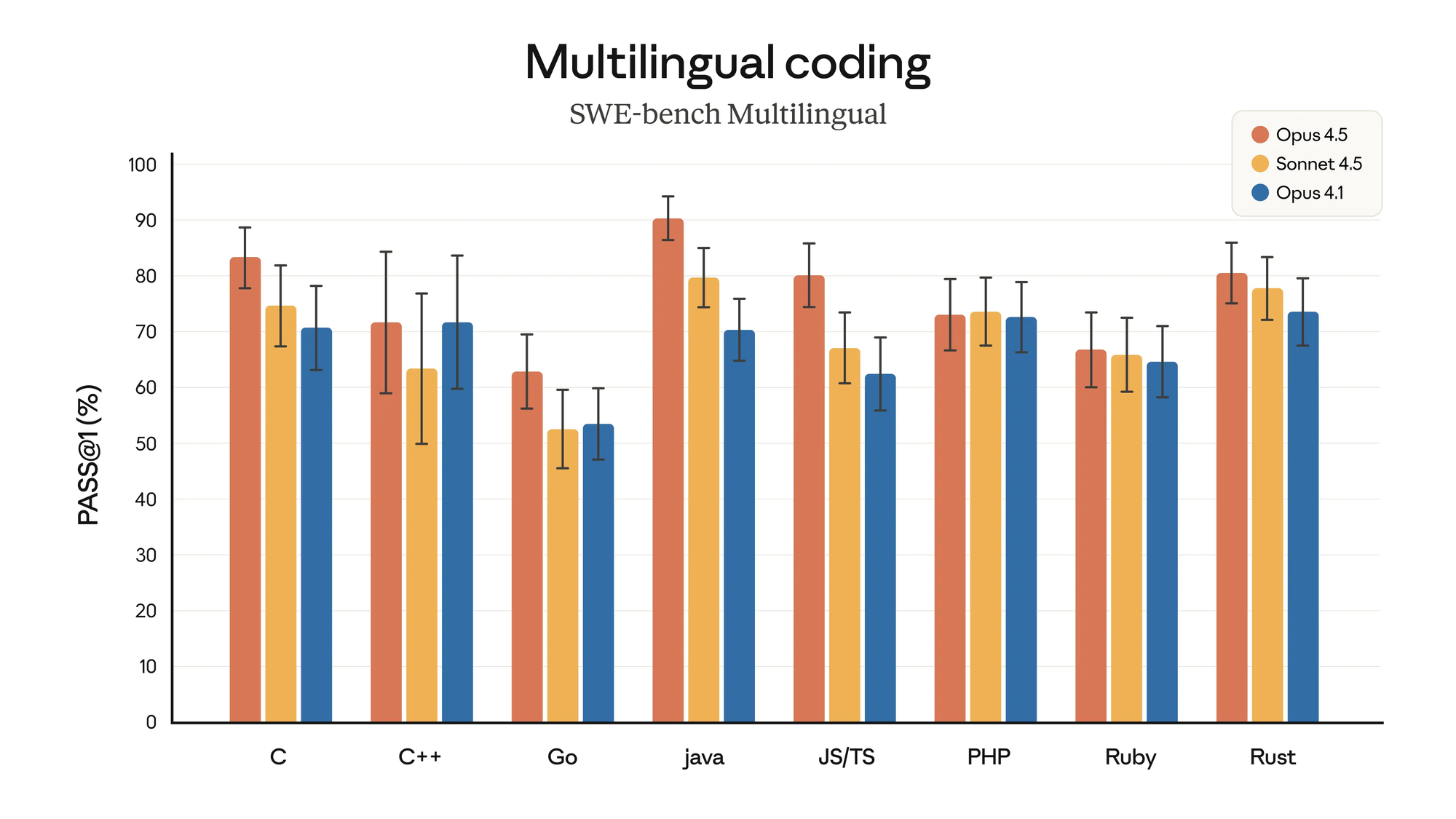
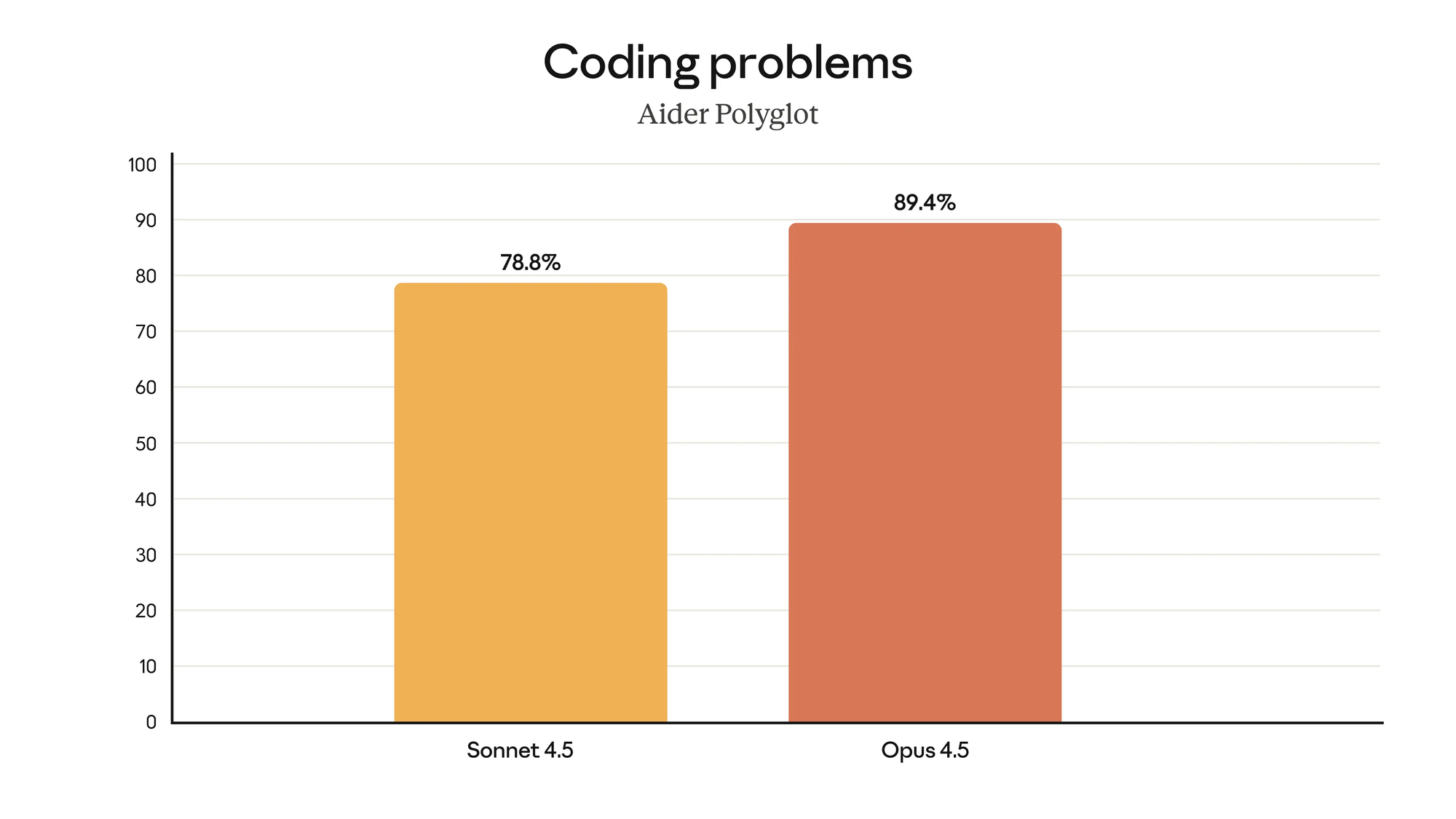
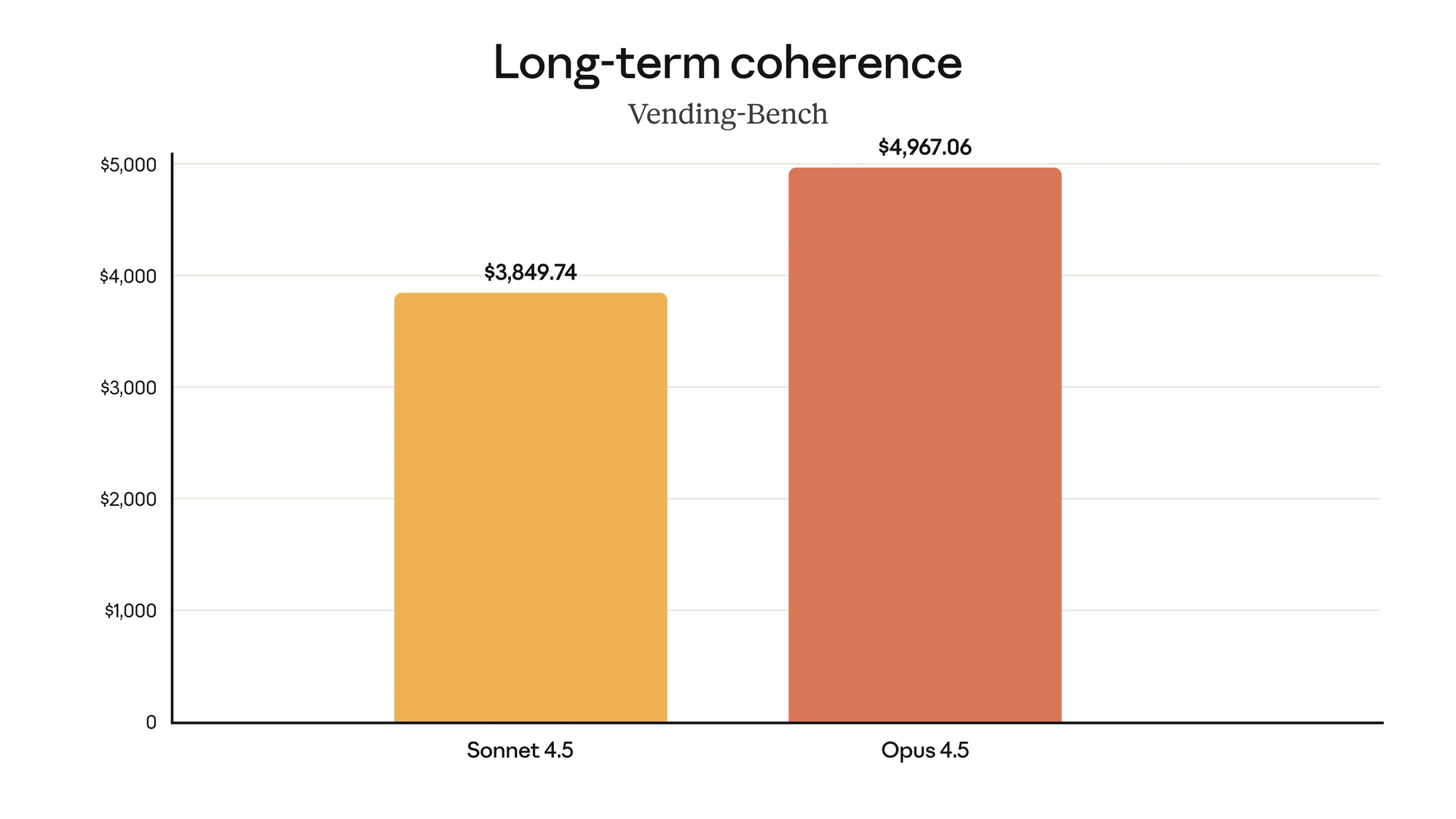
Real People, Real Work: What I’ve Seen
Diving into use cases, Opus 4.5 isn't theoretical—it's transformative for pros grinding daily:
- Dev Teams Shipping Faster: One indie hacker I chatted with fixed a Rails app's auth vulnerabilities across microservices in under an hour. Opus built a plan.md file, ran parallel sessions for testing, and even researched GitHub alternatives. "It asked clarifying questions I hadn't thought of," he said. Perfect for "Claude Opus 4.5 for coding projects."
- Marketers Owning Campaigns: A content lead used it to analyze competitor spreadsheets, generate SEO-optimized briefs, and simulate A/B tests. Output? A full strategy with "Claude Opus 4.5 features for SEO optimization" baked in—keyword clusters, meta tweaks, all in minutes. Cut production time by 65%, with higher E-E-A-T vibes.
- Researchers Tackling the Deep End: For "real-world use cases for Claude Opus 4.5 in marketing" or beyond, it shines in multi-agent setups. I tasked it with a policy analysis: One subagent scraped sources, another debated tradeoffs. Result: A nuanced report on economic impacts, citing ethics without bias. Beats GPT-5's occasional overconfidence.
So… Is Claude Opus 4.5 Actually Worth It?
For casual users? It's overkill. But if your day involves untangling code, strategizing under uncertainty, or automating agentic flows, this model's your unfair advantage.
Ready to redefine your workflow?