
Introducing Claude Opus 4.6: The New Standard for Agentic AI and Professional Work


When Anthropic quietly dropped Claude Opus 4.6 on February 5, 2026, it didn’t come with fireworks — it came with results that quietly changed the conversation.
At Siray.AI we’ve already integrated the model and watched users push it in ways that earlier versions simply couldn’t handle. This isn’t hype. It’s a measurable step forward in sustained reasoning, coding autonomy, massive context handling, and real professional utility.
Today we’re breaking down what makes Claude Opus 4.6 different: the benchmarks that prove it, how it compares to previous Claude models, the practical use cases already delivering value, and why teams are starting to treat it like a senior collaborator rather than just another tool.

What Actually Changed with Claude Opus 4.6
The headline upgrades fall into four clear buckets:
- 1 million token context window (now in public beta)
- Adaptive reasoning that automatically scales thinking depth based on task difficulty
- Stronger agentic behavior — the model plans, self-corrects, uses sub-agents, and stays coherent across very long sessions
- Noticeably better safety tuning without crippling usefulness
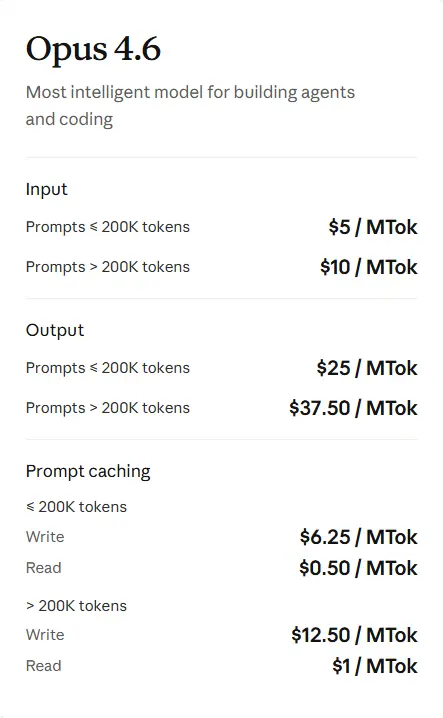
Pricing stays premium ($5 input / $25 output per million tokens), but the efficiency gains mean many teams are actually spending less overall because they need fewer retries and follow-up prompts.
At Siray.AI we’ve made it dead simple to start using Claude Opus 4.6 without managing API keys or dealing with rate limits — just sign in and go. And Siray offers Free Claude Opus 4.6 Key API.
Benchmark Reality Check
Let’s look at the numbers that matter most for real work.
- GDPval-AA (economically valuable professional tasks): +190 Elo over Claude Opus 4.5
- MRCR v2 8-needle 1M context test: 76% retrieval accuracy (vs 18.5% on 4.5)
- SWE-bench Verified: 81.42% over 25 trials
- BigLaw Bench: 90.2% accuracy, 40% perfect scores
- Terminal-Bench 2.0: currently #1 among publicly evaluated frontier models
- Humanity’s Last Exam (hard multidisciplinary reasoning): leads the current leaderboard
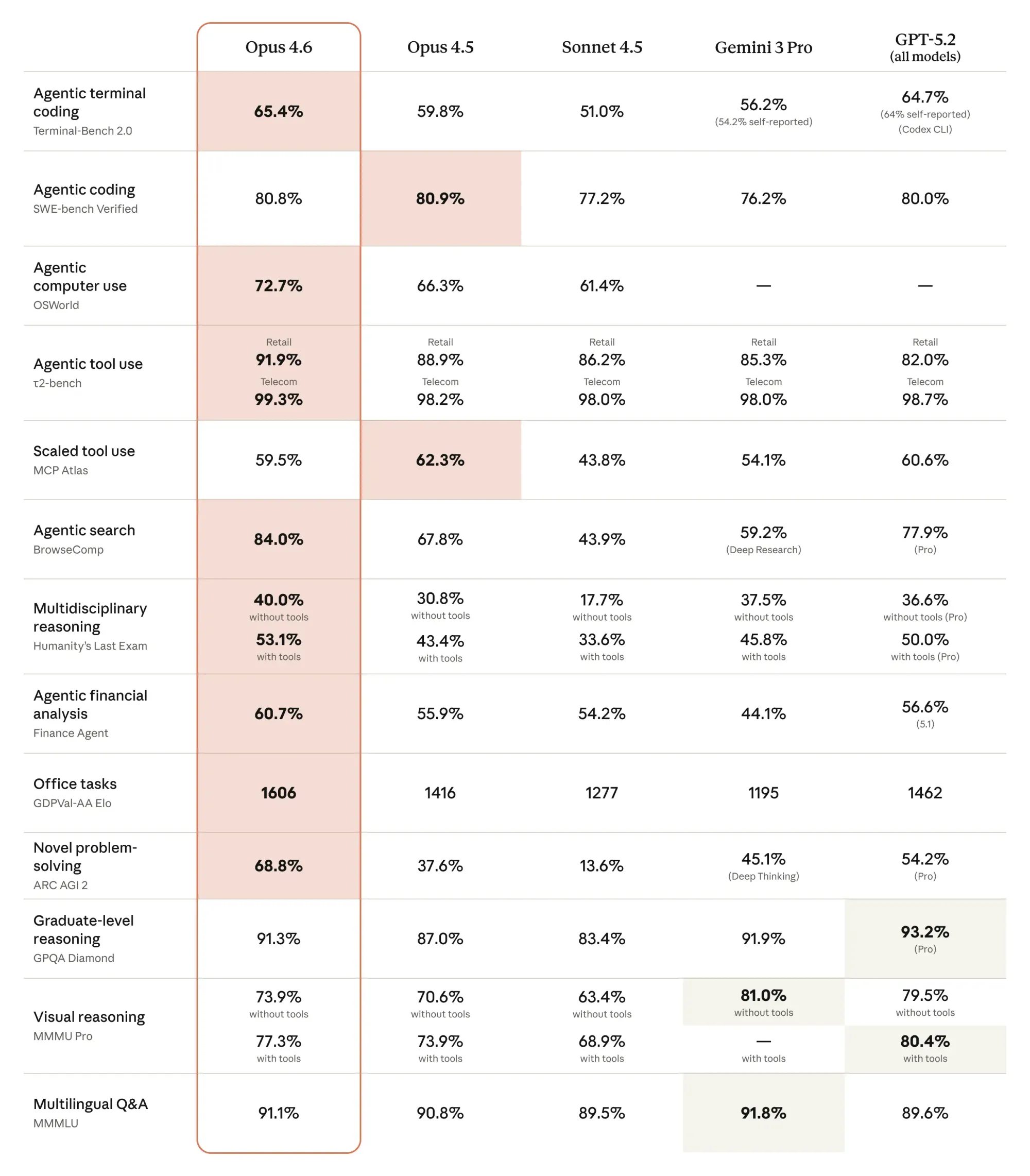
Data pulled from Anthropic’s release notes, Artificial Analysis leaderboard, and independent third-party runs.
The pattern is consistent: Claude Opus 4.6 doesn’t just edge out its predecessor — it pulls away significantly on tasks that require planning over hours (or days), working with enormous documents, or solving problems where the right answer isn’t obvious on the first try.
Claude Opus 4.6 vs Claude Opus 4.5 — The Practical Differences
People always ask: “Is it really worth switching?”
Here’s what teams are actually experiencing:
- Code review & refactoring speed improved by roughly 2× on large codebases
- Ability to stay focused across 300k–800k token sessions without drifting or repeating itself
- Far fewer “I need more context” or “can you start over” moments
- Much stronger performance when asked to autonomously break down and solve multi-step engineering or research problems
- Noticeably better handling of ambiguous requirements (“make this dashboard feel more premium” → actually good taste applied)
In short: 4.5 was excellent. 4.6 feels like it finally crossed into senior-engineer territory on many tasks.
Where Claude Opus 4.6 Is Already Delivering Real Value
Here are the use cases we see most often on Siray.AI right now:
1. Large-scale code migration & modernization
Teams are feeding in 500k+ line legacy codebases and asking the model to propose incremental migration plans, write compatibility layers, and generate tests — all while keeping architectural coherence.
2. Autonomous debugging & root-cause analysis
Give it a failing CI pipeline, full logs, and access to the repo. It reads everything, hypothesizes causes, suggests fixes, and even writes the PR description.
3. Financial & legal research at scale
Analysts upload 10–20 dense PDFs (SEC filings, research papers, contracts), then ask multi-faceted questions that require cross-referencing. The 1M context + strong reasoning make this dramatically more reliable.
4. Cybersecurity red-teaming & vuln discovery
The model is now trusted enough that some teams use it to hunt for logic flaws in open-source libraries — it found real issues in 38/40 deliberately vulnerable code samples during Anthropic’s internal testing.
5. Long-form professional writing & strategy documents
From investor memos to 30-page product requirements docs — users report much higher first-draft quality and far fewer structural rewrites.
6. Multi-agent research & prototyping
Through Claude Code (research preview), teams are spinning up small agent teams that divide work: one plans architecture, another implements, a third writes docs and tests.

A Few Honest Caveats
It’s not magic.
- You still need to give clear, structured instructions for best results
- Very long sessions can become expensive (though context compression helps a lot)
- It’s currently US-only for direct inference (cloud partners expanding soon)
- For ultra-high-volume chat use, lighter models are still more economical
But for the kinds of deep, focused work that actually moves business needles — this is currently one of the strongest options available.
Final Thoughts
Claude Opus 4.6 isn’t just another model release. It’s the first time we’ve seen a frontier model that feels genuinely comfortable operating at the scale and duration that real professional work demands.
Better benchmarks are nice.
Being able to trust it across week-long projects is transformative.
At Siray.AI we’ve made Claude Opus 4.6 immediately accessible — no credit card needed to start, no complicated setup.
You can try Claude Opus 4.6 right now on Siray.AI and see the difference yourself.
Start exploring Claude Opus 4.6 today