
DeepSeek New Model Leak: Is This the V4 That Will Redefine Open-Source AI?


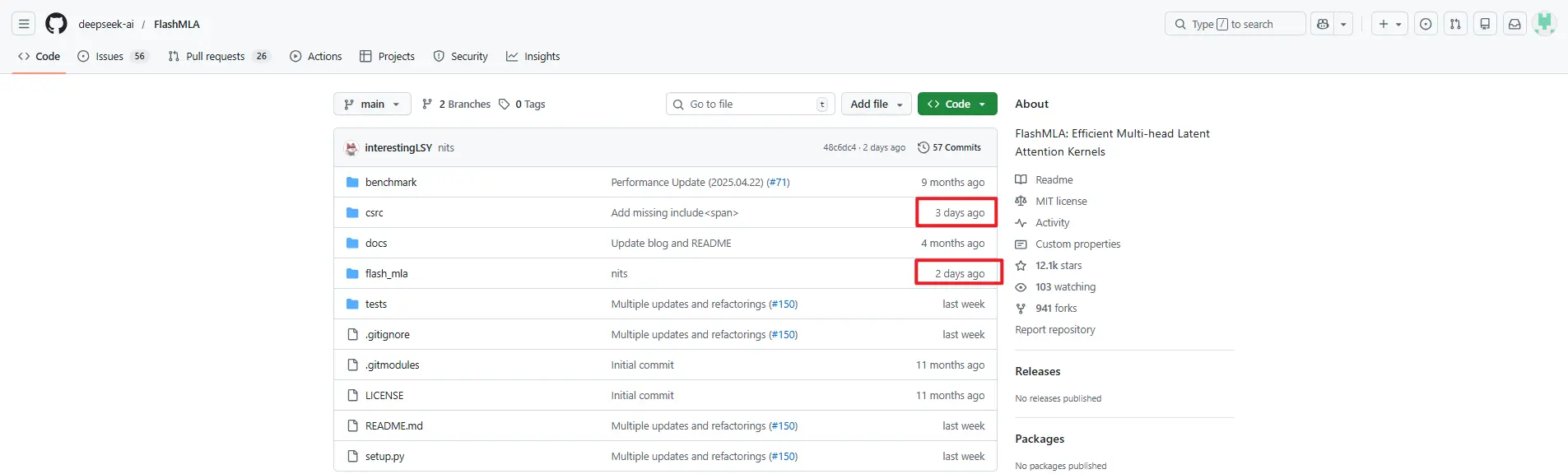
It's been exactly one year since DeepSeek dropped R1, the model that shocked the industry with reasoning power rivaling OpenAI's o1 at a fraction of the cost. On January 20, 2026, the community lit up again. DeepSeek quietly updated their FlashMLA repo (their high-performance MLA inference kernel), and the code is full of references to something called "Model1".
This isn't a minor patch. From everything we can see, Model1 is the early engineering name for DeepSeek-V4 — and it looks like a genuine architectural leap.
We been following DeepSeek closely since the V2 days. What makes this leak exciting isn't just hype — it's the technical signals. Let's break down what the code actually tells us, how it compares to V3.2, and what it could mean for developers and API users in 2026.
The Leak: What DeepSeek's FlashMLA Code Reveals
The strongest evidence comes from a major commit in the FlashMLA repository. The code now contains dozens of references to MODEL1 alongside V32 (the internal tag for V3.2). Developers who ran code analysis noticed several breaking changes that don't make sense for a simple V3 update.
Key architectural shift:
- V3.2 used an asymmetric MLA with 576 dimensions (128 RoPE + 448 latent)
- Model1 reverts to a clean 512-dimensional head_dim — the industry standard
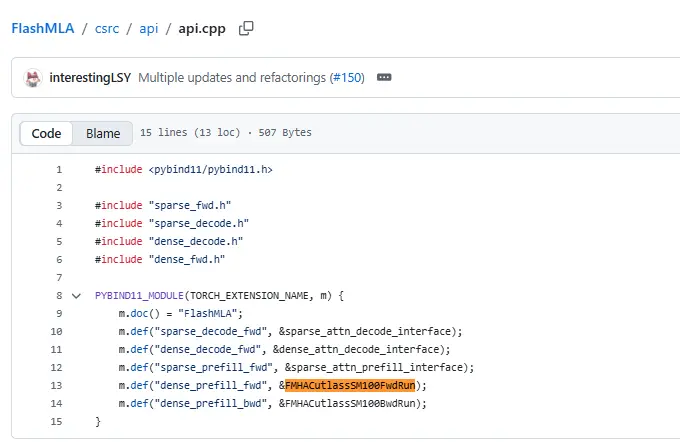
This isn't a downgrade. It suggests DeepSeek is optimizing for hardware compatibility (especially NVIDIA's new Blackwell SM100 architecture) and simpler, more efficient latent compression. The code now fully supports CUDA 12.9 and Blackwell-specific kernels (FMHACutlassSM100FwdRun interface).
New Tech That Matters: Sparse MLA, VVPA, and Engram
This is where things get really interesting:
- Token-level Sparse MLA (with parallel sparse + dense modes) — Allows mixing sparsity levels per token. Huge for throughput.
- FP8 KV Cache (with bfloat16 matmul) — Massive memory savings for long-context work while preserving precision where it counts.
- VVPA (Value Vector Position Awareness) — Directly addresses position information decay in long sequences. Traditional MLA tends to lose positional signal over very long context. VVPA fixes that.
- Engram — One of the most intriguing additions. It seems to be a new memory/compression mechanism that solves the classic trade-off between high throughput and long-context quality.
On hardware:
- B200 (Blackwell): Sparse MLA hitting ~350 TFlops (not even fully optimized yet)
- H800: Dense MLA reaching 660 TFlops
These are inference kernel numbers, not full model benchmarks — but they indicate Model1 is built from the ground up for next-gen GPUs.

Comparison: V3.2 vs Model1 (Expected V4)
DeepSeek V3.2 strengths:
- Excellent reasoning + search hybrid
- Strong multimodal
- Great price/performance
Where Model1/V4 appears superior:
- Better long-context coherence (thanks to VVPA + Engram)
- Significantly higher inference throughput & lower memory footprint
- Optimized for Blackwell → future-proof hardware efficiency
- Likely even stronger coding/software engineering (DeepSeek has been teasing this focus for months)
Early rumors from internal tests suggest V4 could be a "coding monster" — potentially outperforming GPT-4o and Claude 3.5/4 in complex repo-level tasks.
Real-World Use Cases
For developers and teams:
- Long-document analysis & RAG — Engram + VVPA should shine here
- High-volume inference — Lower cost per token due to FP8 + sparsity
- Agentic workflows & coding agents — Expected big leap
- Multimodal pipelines — Cleaner architecture should help stability
If you're using DeepSeek via API today, this generation could bring meaningful cost reductions and better reliability at scale.
Release Timing
Most credible sources now point to mid-February 2026, nicely timed with the Lunar New Year (around Feb 17). DeepSeek has a habit of dropping major models during Chinese holidays — they did it with previous releases.
Summary
Model1 isn't just another incremental update. The architecture standardization, Blackwell-native support, new mechanisms like VVPA and Engram, and token-level sparse MLA point to one of the most ambitious open-source model releases we've seen.
DeepSeek continues to prove that you don't need a trillion-dollar compute budget to push the frontier. Efficiency, clever architecture, and ruthless optimization remain their superpower.
While we wait for the official V4 launch, you can already run the latest DeepSeek models (V3, V3.2, and many variants) plus 300+ other top models through one unified API on Siray.ai — often at 50-70% lower cost than direct providers, with excellent uptime.