
GLM-4.7: The New Open-Source King of Coding and "Vibe" Generation


The landscape of Artificial Intelligence moves with such velocity that "state-of-the-art" often feels like a moving target. However, every so often, a release arrives that doesn’t just shift the needle—it resets the standard. The launch of GLM-4.7 by Zhipu AI is one of those moments. As an open-source powerhouse, GLM-4.7 isn't just competing with the industry's closed-source giants; in many critical workflows, it is beginning to lead.
For developers and tech enthusiasts, the question is no longer just about which model has the most parameters. It’s about which model can actually do the work. Whether you are building complex agentic workflows or looking for a "vibe" in your front-end design, GLM-4.7 offers a compelling case for being your next go-to assistant. You can experience the full power of this model firsthand at Siray.AI, where we provide a seamless environment to test its capabilities for free.

The Benchmark Breakdown: Fighting at the Frontier
When we look at the hard data, GLM-4.7’s performance is nothing short of impressive. According to recent data from Artificial Analysis and official technical reports, GLM-4.7 has made a historic leap over its predecessor, GLM-4.6, and is now trading blows with GPT-5.1 and Claude 3.5 Sonnet.
One of the most grueling tests in the AI world today is Humanity’s Last Exam (HLE), a benchmark designed to be nearly impossible for anyone without advanced academic reasoning. GLM-4.7 achieved a score of 42.8%, representing a massive 12.4% improvement over GLM-4.6. To put that in perspective, this score places it essentially neck-and-neck with GPT-5.1 (42.7%) and significantly ahead of Claude 3.5 Sonnet (32.0%) in complex reasoning tasks.
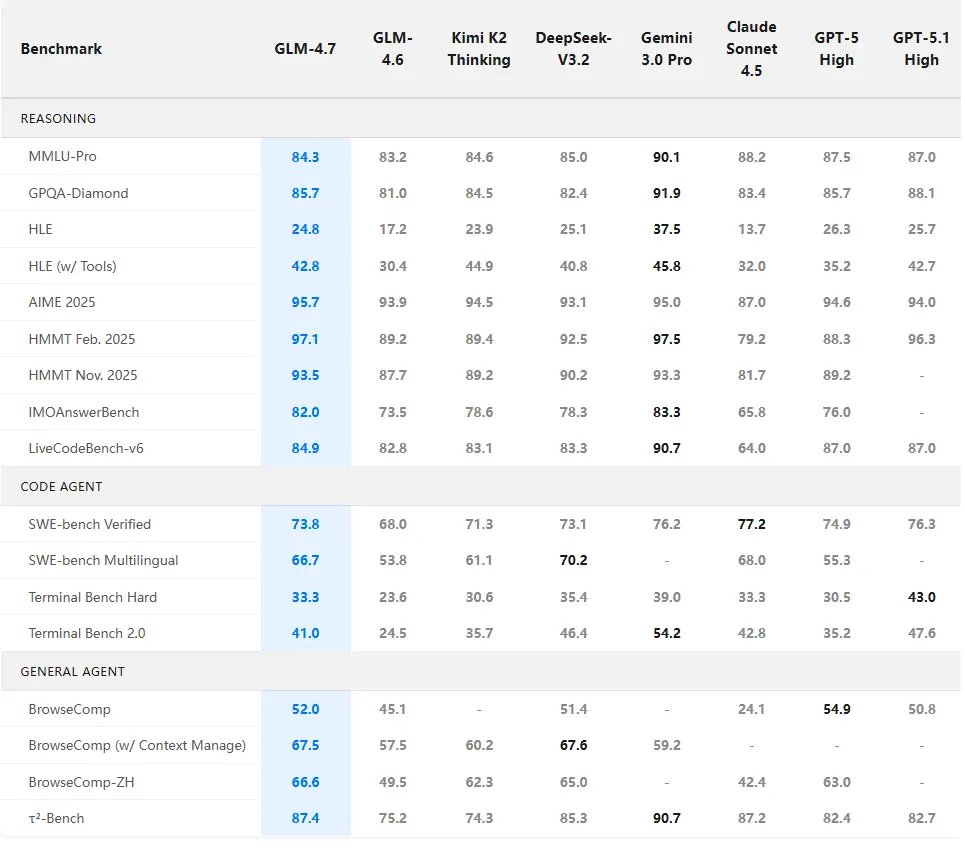
In the coding arena, the metrics are even more practical. On SWE-bench Verified, the gold standard for real-world software engineering, GLM-4.7 reached 73.8%. But where it truly shines is in multilingual coding, where it scored 66.7%—a nearly 13% jump from previous versions. This makes it perhaps the most capable model for global development teams handling mixed-language codebases.
"Vibe Coding" and UI Mastery
While benchmarks tell the story of logic, they often fail to capture the "feel" of AI-generated output. Zhipu AI has addressed this with a concept they call "Vibe Coding." Traditional LLMs often produce functional but visually uninspired front-end code. GLM-4.7 has been specifically tuned to understand aesthetics.
It generates cleaner, more modern web pages with high-contrast dark modes, sophisticated typography, and better layout accuracy. In office productivity tests, its 16:9 PPT layout accuracy jumped from 52% to a staggering 91%. For developers using Siray.AI, this means the code you generate isn't just "runnable"—it's "production-ready" from a design perspective.
Agentic Intelligence: Thinking Before Acting
What truly sets GLM-4.7 apart is its Interleaved Thinking architecture. Unlike older models that may "hallucinate" mid-task, GLM-4.7 is designed to reason before it acts. It introduces three distinct modes:
- Interleaved Thinking: The model pauses to reason before every response and tool call.
- Preserved Thinking: It retains reasoning blocks across multi-turn conversations, reducing information loss in long-horizon tasks.
- Turn-level Thinking: Gives users control over the cognitive budget—enabling deep reasoning for complex bugs and disabling it for quick, lightweight requests.
On the τ²-Bench (Tool Use), GLM-4.7 achieved an open-source SOTA score of 87.4, proving it can reliably plan and execute multi-step workflows like searching the web, analyzing data, and writing a report without losing the original objective.
Use Cases: From Prototype to Production
How does this look in the real world?
1. Autonomous Coding Agents: With a 41% score on Terminal Bench 2.0, GLM-4.7 is an elite partner for tools like Claude Code or Cline, capable of navigating file systems and executing terminal commands with high reliability.
2. Rapid UI Prototyping: Use it to generate structurally complete React or Tailwind frameworks that look like they were designed by a human, not a bot.
3. Complex Data Analysis: Its ability to handle a 200,000-token context window means you can feed it entire codebases or massive technical documents for analysis.

Why Use GLM-4.7 on Siray.AI?
At Siray.AI, we believe the best way to understand a model's potential is to use it. GLM-4.7 represents the democratization of frontier-level intelligence. By offering this model, we allow our users to leverage a system that is roughly 70% the cost of proprietary models while delivering comparable, and sometimes superior, results.
Whether you are a developer looking to automate your workflow, a researcher testing the limits of LLM reasoning, or a designer looking for a "vibe" boost, GLM-4.7 is the tool you've been waiting for.
Summary
GLM-4.7 is more than just an incremental update; it is a declaration that open-source AI has arrived at the frontier. With top-tier scores in the HLE reasoning benchmark, a revolutionary approach to UI generation through "Vibe Coding," and robust agentic stability, it is a model that demands a place in your development stack.
The era of choosing between "open" and "powerful" is over. With GLM-4.7, you get both.
Ready to see what the next generation of AI can do?