
GPT-4.1: The Only Review You Need (SWE-Bench, Cost, Speed)


Let’s be honest: the pace of AI innovation can feel exhausting. Every few months, we hear about a “revolutionary” new model. But for business leaders and developers who need stability, performance, and real return on investment (ROI), the question is always the same: Is this actually a game changer, or just another incremental update?
Today, we're talking about a genuine shift. The arrival of the GPT-4.1 model family isn't just about higher scores on a leaderboard; it’s about finally delivering on the promise of reliable enterprise-grade AI.
At Siray.AI, our mission is to cut through the noise and provide the most effective tools immediately. That's why we're making the entire GPT-4.1 series—the flagship, the efficient Mini, and the ultra-fast Nano—available to our users. We want to ensure you're working with the absolute frontier of technology.
This post is your essential guide. We’re going beyond the marketing claims to review the core GPT-4.1 features, examine the crucial GPT-4.1 benchmark scores (especially in coding and reasoning), and lay out the groundbreaking GPT-4.1 use cases that will define the next two years of business automation. If you’re trying to figure out the best AI model for writing 2025 or weighing the real GPT-4.1 cost vs performance for business, keep reading. This is the analysis you need to make your next big strategic move.
The Defining Leap: Why GPT-4.1 Matters So Much
The launch of GPT-4.1 is best understood as a moment of maturity for large language models. The developers haven't just made the model "smarter" in an abstract sense; they’ve made it more professional. It’s engineered specifically to handle the messy, high-stakes tasks that define enterprise work.
Previous models were great at brainstorming and drafting. GPT-4.1 is built to execute complex, multi-step projects with a level of precision we haven't seen before. The focus is squarely on three core areas: reliable code, accurate instruction following, and massive context management. These features directly address the biggest headaches developers faced with earlier models.
1. The Code Whisperer: Unprecedented Reliability in Software Tasks
For any tech company, a model that can reliably write and fix code is the ultimate productivity lever. This is where GPT-4.1 truly pulls ahead of the pack. It moves from being a helpful coding assistant to being an indispensable, autonomous engineer on your team.
The Evidence: Benchmark Breakdown
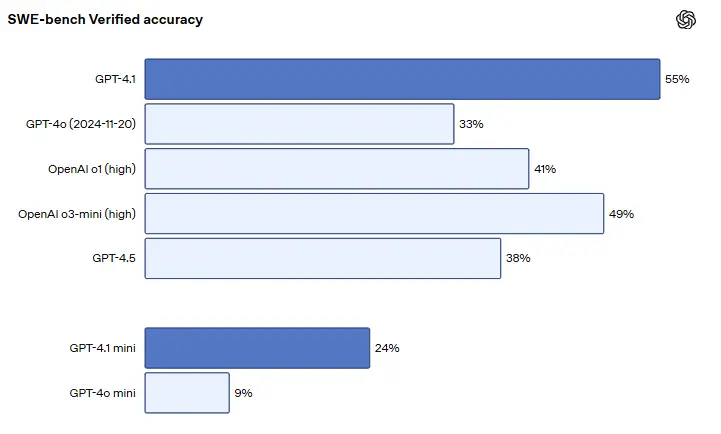
We look to third-party data to ground this claim. The SWE-bench Verified benchmark, which tests an AI model's ability to solve real-world GitHub issues within existing codebases, is the gold standard. As reported by specialized sources like artificialanalysis.ai:
- GPT-4.1 achieved a verified score of 54.6%.
- The closest comparable predecessor, GPT-4o, scored only 33.2%.
That’s over a 21 percentage-point leap! In the world of competitive AI, that's practically a lifetime of progress.
But there’s a more telling metric for day-to-day software maintenance: Code Diff Accuracy. In production environments, engineers rarely rewrite entire files; they make surgical, minimal changes. GPT-4.1 excelled here, showing a massive improvement in only modifying the necessary lines of code. This dramatically reduces the risk of introducing new bugs, which for high-stakes software answers the critical question: best large language model for code generation 2025.
2. When Instructions Are Sacred: Precision on Demand
In the real business world, a chatbot that deviates from its instructions is a liability. You need an AI that can handle multi-step workflows, stick to complex formatting, and rigidly adhere to compliance rules.
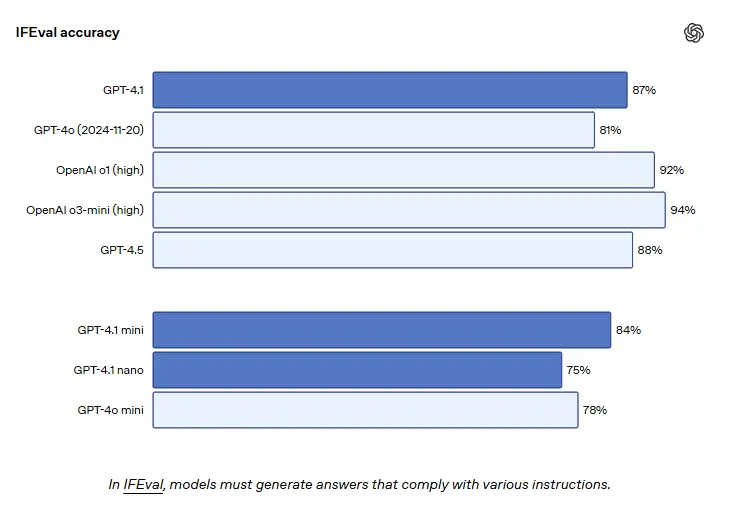
GPT-4.1’s instruction adherence is fundamentally better. When tested on multi-step instructions that included specific constraints (like "use XML output format" or "do not mention this client"), the model correctly followed the instructions a remarkable 49% of the time, a significant jump from its predecessor's 29%. Furthermore, its compliance with negative constraints (e.g., "avoid jargon") was tested at 87.4% on the IFEval benchmark.
What this means in practice is that you can build highly reliable agentic workflows—AI systems that chain together multiple tools and steps—with much less risk of failure. This is key for companies asking how to integrate GPT-4.1 into customer service or automated legal drafting. Reliability at this level is the new premium feature.
3. A Memory Like an Elephant: The 1 Million Token Context Window
The constraint of previous models was always their short-term memory. They’d forget the beginning of a long meeting transcript or the details from a document they processed moments ago.
With GPT-4.1, the maximum context window size has ballooned to an extraordinary 1 million tokens. To put that in perspective, that’s enough memory to process an entire book, a massive legal brief, or weeks of complex correspondence in a single prompt.
This capability isn't just a convenience; it's transformative for knowledge-intensive industries:
- Financial Auditing: Imagine uploading an entire quarter’s financial transaction logs, all regulatory documentation, and all internal communications to a single model instance. The model can then cross-reference everything to spot a dependency or anomaly with a single query.
- Deep Research: Scientists can feed the model hundreds of technical papers to generate novel hypotheses, confident that the AI hasn't forgotten the introduction of the 500th document by the time it reads the conclusion.
- Next-Gen Service Agents: Customer service agents can instantly access the full, multi-day history of a complex client relationship, ensuring continuous, informed support. This enhanced memory is what makes the Siray.AI platform with GPT-4.1 model such a powerful solution for enterprise knowledge retrieval.
4. Smart, Fast, and Affordable: The Cost-Performance Sweet Spot
Is GPT-4.1 expensive? Surprisingly, the answer is no, not when you factor in the efficiency. This new architecture is optimized for performance and scale, making it a compelling argument for moving away from older, less efficient models.
For instance, when debating GPT-4.1 vs Claude Opus benchmark for creative writing or purely technical tasks, the GPT-4.1 family offers flexibility through its multiple sizes:
| Model Variant | What's the Key Takeaway? | Cost/Speed Advantage (vs. GPT-4o) | Context Window | Best Use Case |
| GPT-4.1 | The best-in-class performance for complex reasoning and code. | 26% lower cost for equivalent performance. | 1 Million Tokens | Mission-critical agents, Expert coding, Deep analysis. |
| GPT-4.1 mini | Performance that matches or beats the old flagship (GPT-4o) for far less. | 83% cheaper, dramatically lower latency. | 1 Million Tokens | High-volume APIs, Entry-level chatbots, Efficient summarization. |
| GPT-4.1 nano | Unbelievably fast and cheap. | The most affordable model released to date. | 1 Million Tokens | Quick classification, Autocompletion, Simple data parsing where speed is everything. |
The GPT-4.1 mini is the secret weapon here. It offers performance levels that outperform the previous top-tier model while drastically cutting the cost and latency. For high-volume deployment, this shifts the entire economic model of using AI.
Real-World Impact: Revolutionizing Operations with GPT-4.1
The advanced capabilities of this new series unlock a tier of applications that were previously relegated to science fiction or brittle, proof-of-concept demos. With GPT-4.1, they become reliable business tools.
1. The Autonomous Development Pipeline
The massive jump in coding accuracy and the ability to maintain context over vast codebases means genuine autonomous software development is now within reach. An agent powered by GPT-4.1 can be tasked with a complex feature, pull the entire repository, write the code, run its own internal tests, and submit a pull request for human review. This answers the query is GPT-4.1 faster than GPT-4 Turbo not by looking at seconds per token, but by looking at hours of human engineering time saved.
2. High-Fidelity Content and Knowledge Systems
When we conduct a GPT-4.1 review for enterprise applications, its strength in long-form content is undeniable. It can absorb complex internal style guides, technical specifications, and compliance rules and adhere to them flawlessly over a 10,000-word document. For generating technical manuals, personalized marketing campaigns, or extensive training materials, the quality is consistent and requires minimal human clean-up. This is the foundation for a robust Generative AI updates 2025 strategy.
3. Next-Generation Multimodal Intelligence
Beyond text, the GPT-4.1 family is fully multimodal. Its ability to process and reason over video, audio, and images has also seen targeted improvements.
Example in Logistics: A major logistics firm could feed GPT-4.1 hours of dockside security footage (video input) and ask it to cross-reference the activity against a shipping log (text input). The 1M token context window allows the model to analyze long video streams for anomalies—like a container being moved too early or too late—with high precision. This is a dramatic step forward in practical applications of GPT-4.1 in finance (auditing transactions) and supply chain security.
4. Customizing Your Edge with Secure Fine-Tuning
Every business is unique, which means every model needs to be unique. Siray.AI understands that security and domain-specific knowledge are paramount. We offer a streamlined, secure environment for developers to fine-tune the GPT-4.1 and GPT-4.1 mini models on your proprietary data. This is how you move from a powerful generalist AI to a specialized, competitive advantage that speaks your company's language and adheres to its specific regulatory framework. When you deploy the Siray.AI platform with GPT-4.1 model, you're not just getting a new model; you’re getting a new capability entirely.
Experience the Future of AI Today
GPT-4.1 is the new baseline. It represents the point where AI transitions from a novelty tool to a mission-critical platform component. The verifiable benchmark data confirms its superior performance in coding and complex instruction following, while the 1 million token context window opens up applications that were previously impossible. The economic efficiency of the Mini and Nano models means this power is accessible at every level of your operation.
The time for cautious waiting is over. Integrating GPT-4.1 is simply a necessary step to maintain a competitive position in a world increasingly powered by autonomous agents and intelligent automation.
We don't want you to just take our word for it. We want you to feel the difference a 1-million-token context window makes. We want you to see the accuracy of the new coding benchmarks in action.
Take the GPT-4.1 family for a test drive and discover how its precision can transform your most challenging enterprise workflows.