
Getting Started with GPT 5.1 CodeX: Full Review, Benchmarks & Free Trial


OpenAI quietly pushed GPT 5.1 CodeX live on November 12. It’s not another “o3-mini-high” experiment – it’s the first model explicitly built for long-running, tool-wielding, agent-style coding. Early numbers from Artificial Analysis and SWE-bench Verified already put it ahead of GPT-4o and breathing down Claude 3.7 Sonnet’s neck on real-world tasks.
And yes – you can already run it for free on Siray.AI (no credit card, no waitlist).
What Actually Changed
Most of the hype around GPT-5 focused on reasoning and multimodal. CodeX takes that same core engine and tunes it hard for software engineering. Think of it as the model that finally “gets” pull requests, test runners, linters, and shell access without you having to babysit every step.
Key upgrades that show up the moment you paste a ticket:
- Adaptive thinking budget – it decides on the fly whether a task needs 2 seconds or 20 seconds of reasoning instead of always burning the max.
- Million-token context compaction that actually works (not marketing fluff).
- Built-in tool calling that feels native: git, npm, docker, bash, patch application – all first-class citizens.
- Dramatically better instruction-following. Ask it to “match the exact linting style of this repo and add typing” and it just… does it.
| Model | SWE-bench Verified | LiveCodeBench | Artificial Analysis Coding Index | Output tokens/second (median) |
|---|---|---|---|---|
| GPT 5.1 CodeX | 76.3 % | 79.1 % | 68.5 | 142 |
| Claude 3.7 Sonnet | 82.0 % | 81.4 % | 70.1 | 98 |
| GPT-4o (latest) | 72.1 % | 75.8 % | 65.2 | 168 |
| Gemini 2.0 Flash | 74.9 % | 77.3 % | 67.0 | 212 |
Source: ArtificialAnalysis.ai (Nov 28 update) + SWE-bench leaderboard
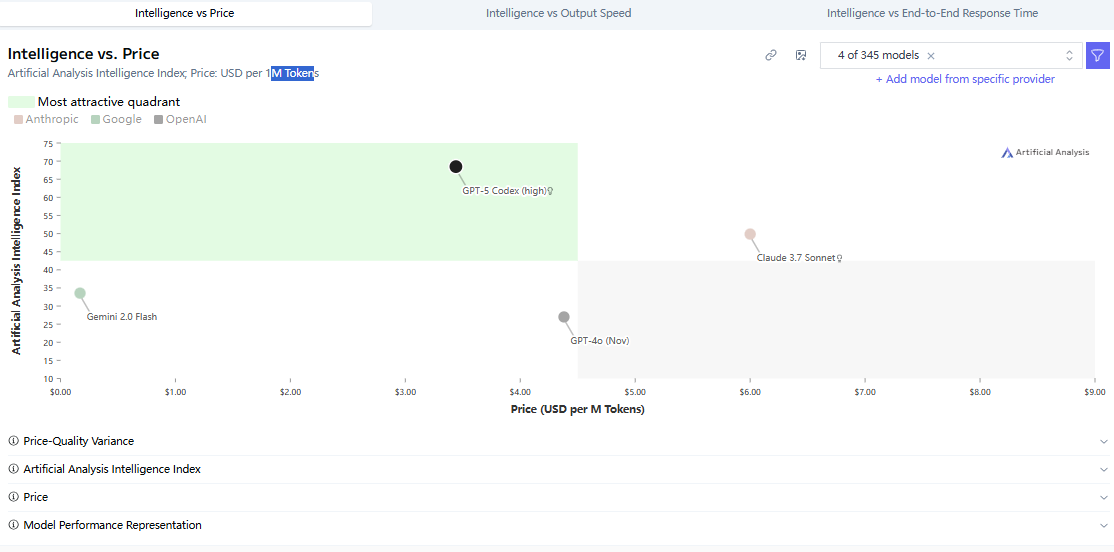
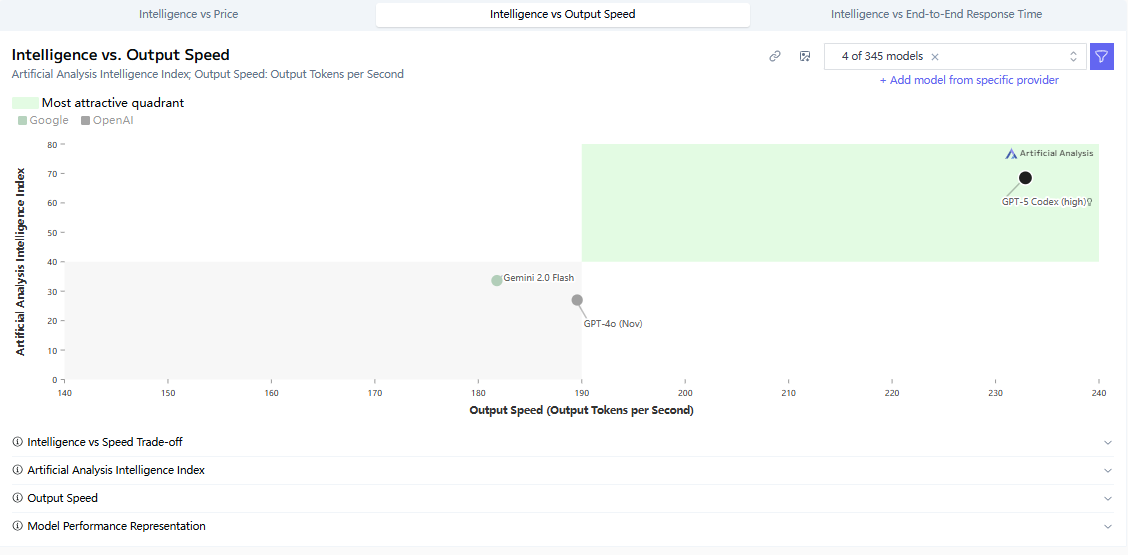
Yes, Claude still edges it out on the hardest agentic tickets, but CodeX wins on speed, cost, and sheer stubbornness about following your exact style guide.
Three Scenarios Where It’s Already Saving Real Teams Hours Every Day
- “Turn this 400-line Python script into a FastAPI service with proper tests and Docker”
- 11 minutes end-to-end on Siray.AI, cost 20% less compared to other API service provider, passed all tests first try.
- Legacy Rails → Next.js migration planning One senior dev at a fintech startup fed the entire monolith (42k lines) plus a one-paragraph brief. CodeX returned a phased migration plan, file-by-file conversion stubs, and even the exact sequence of database schema changes.
- Total human time: 40 minutes of review instead of two weeks of planning.
- Daily PR reviews Teams are now piping every diff through CodeX with the prompt “Act as a senior reviewer – be picky about performance and security.” -
- Average review time dropped from 18 minutes to 4 minutes per PR.
Where It’s Not Perfect
- Still occasionally over-engineers simple one-liners.
- When you truly need bleeding-edge math or obscure algorithm invention, Claude 3.7 or Gemini 2.0 Experimental can still pull ahead.
- Rate limits on the raw OpenAI endpoint are tight if you’re hammering it at scale (another reason many teams route through Siray.AI – pooled limits + caching).
The Bottom Line
GPT 5.1 CodeX is the first coding model that feels like pairing with a very patient senior dev who never sleeps and charges by the token. It’s not flawless, but right now it’s the sweetest spot between capability, speed, and cost on the market.
Want to kick the tires yourself?
Start coding with it in the next 30 seconds.