
GPT 5.2: The Model That’s Tying the Score on Human Expertise


In the rapidly evolving landscape of Large Language Models (LLMs), the term "frontier model" is constantly redefined. Just when the market was stabilizing around the impressive capabilities of Claude Opus 4.5 and Gemini 3 Pro, OpenAI delivered a decisive move with the release of GPT-5.2. This isn't a pivot towards flashier consumer features; it’s a targeted, deep investment in the core competency that matters most to businesses: reliable, complex problem-solving.
For CTOs, product leaders, and developers, the question isn't whether to use AI, but which model offers the most reliable return on investment (ROI). With GPT-5.2, the conversation shifts from mere text generation to full-scale enterprise automation, where the model performs the role of a senior colleague, not just a capable assistant.
At Siray.AI, we have been working closely with early access partners and the API to integrate GPT-5.2 and understand its performance profile. Our analysis confirms that this model sets a new standard for enterprise AI, particularly in tasks requiring deep reasoning, reliable execution, and structured output.
The Core Breakthroughs—Reasoning and Benchmarks
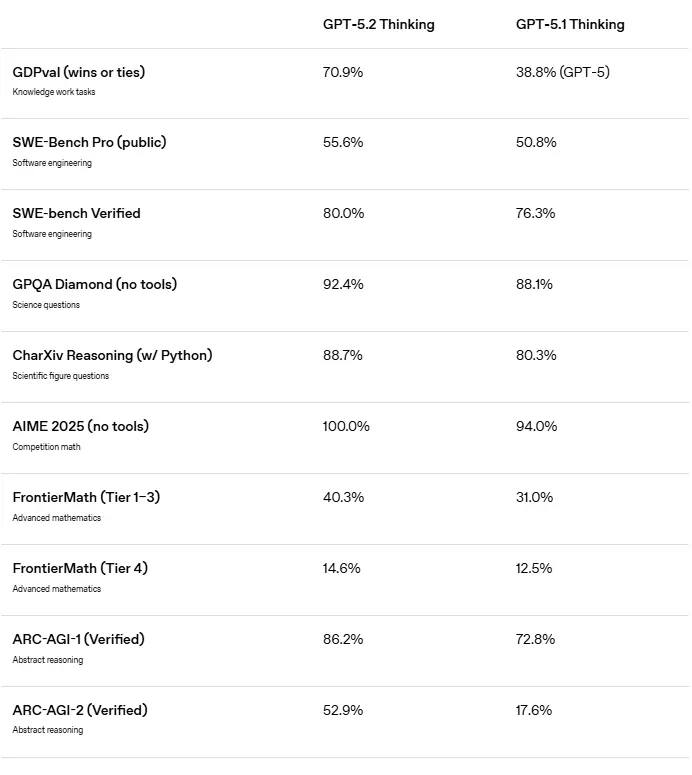
The headline news surrounding GPT-5.2 is its performance against benchmarks that truly test abstract and complex reasoning, areas where previous models often struggled. OpenAI’s internal data, supported by initial independent evaluations, paints a clear picture: the new architecture is a significant step forward.
The Battle of the Giants: GPT-5.2 vs Gemini 3 Pro vs Claude Opus 4.5
The competition for the title of "most intelligent AI" is fiercely concentrated in three areas: abstract reasoning, coding efficiency, and overall knowledge work performance.
- Abstract Reasoning (ARC-AGI-2): This benchmark is the true test of fluid intelligence, pushing models to solve novel problems that cannot be solved by simply memorizing training data. The initial data is striking. Where competitors like Claude Opus 4.5 and Gemini 3 Pro showed strong results, the GPT-5.2 Pro variant is demonstrating a noticeable lead. This elevated performance in GPT-5.2 abstract reasoning power is critical for businesses in R&D, strategic consulting, and scientific discovery.
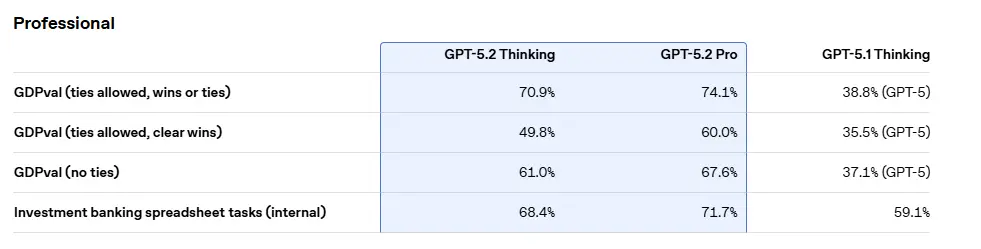
- Knowledge Work (GDPval): OpenAI introduced the GDPval benchmark to measure performance on well-specified, real-world tasks across dozens of occupations. The claim is that GPT-5.2 meets or exceeds human industry professionals in over 70% of these tasks. This shift—from simple QA to complex, multi-faceted knowledge work—is where the real economic value of this model lies.
- Coding Proficiency (SWE-Bench): For software development teams, reliable code generation and bug fixing are paramount. While Claude Opus 4.5 previously held a strong lead on certain coding benchmarks like SWE-Bench Verified, GPT-5.2 coding performance SWE-Bench has closed the gap significantly, achieving a solve rate in the 80% range for the most challenging tasks. Developers can now rely on the model for more complex tasks, such as refactoring large codebases or reliably debugging production code.
The Enterprise Advantage—Agentic Workflows and Reliability
For any enterprise to confidently deploy AI, the system must be reliable, predictable, and capable of sustained, multi-step execution. This is where GPT-5.2 for business automation truly shines.
From Chatbot to Executive Agent
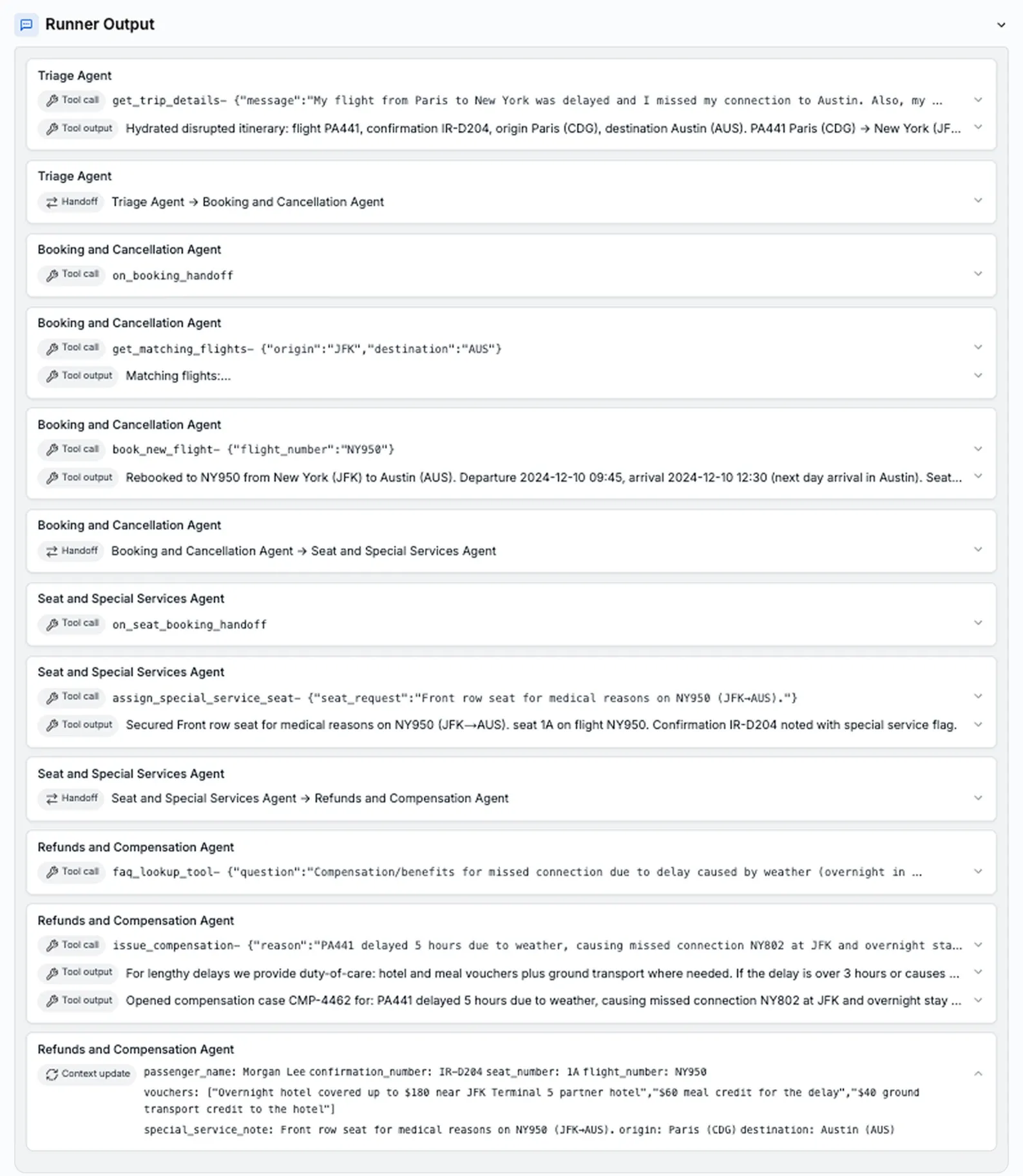
The most significant architectural upgrade is the model's capacity for GPT-5.2 agentic execution. Previous models were excellent at planning tasks but often stumbled during execution, leading to "context drift" or failure when using multiple external tools.
GPT-5.2 introduces a more robust internal planning mechanism that ensures better context-awareness over long inputs, such as multi-chapter documents or large code repositories. This capability enables powerful GPT-5.2 for multi-step workflow orchestration, allowing the model to:
- Ingest: Read a 200-page legal contract (leveraging its robust GPT-5.2 context window size and performance).
- Plan: Outline a three-step action plan (e.g., Identify risk clauses, Summarize regulatory compliance, Extract all signatory names).
- Execute: Use separate retrieval tools, a database query tool, and a spreadsheet generation tool to produce a final, structured output—all without user intervention.
This level of structured, tool-grounded output transforms the model into a true production-ready agent. It shifts the paradigm from simple Q&A to reliable, autonomous execution of critical business processes.
The Power of the Variants: Thinking vs. Pro
OpenAI released GPT-5.2 in two primary variants—the standard GPT-5.2 Thinking and the highly optimized GPT-5.2 Pro.
The Thinking variant is the workhorse, offering lower latency and superior efficiency for everyday tasks like technical writing, summarization, and routine code assistance.
The Pro variant, however, is a game-changer. It leverages scaled, test-time compute to deliver the most comprehensive and accurate answers. For high-stakes tasks—such as financial modeling, contract review, or complex scientific research—the performance gap between GPT-5.2 Pro vs Thinking benchmarks justifies the higher computational cost. Companies building AI assistants that handle the most demanding GPT-5.2 for knowledge work will find the Pro model essential.
Cost and Adoption—The Siray.AI Advantage
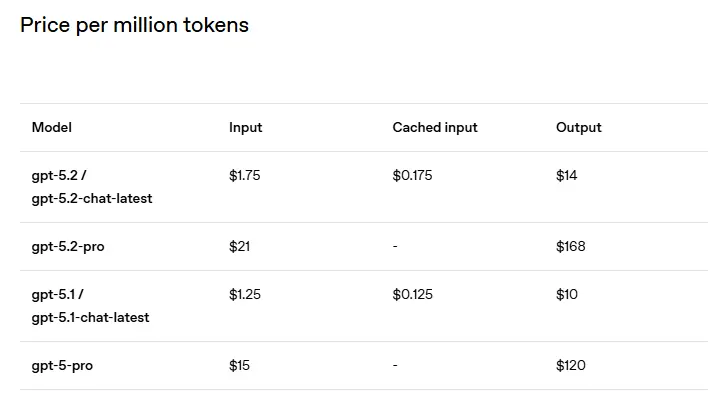
A common concern with frontier models is the expense. Is GPT-5.2 worth the cost increase over GPT-5.1? For most mission-critical tasks, the answer is unequivocally yes, due to the reduction in human oversight and the increased accuracy. However, managing the GPT-5.2 API pricing cost is vital for large-scale deployments.
The pricing structure for GPT-5.2 shows a slight increase over its predecessor, reflecting the higher compute required for its advanced reasoning. For standard use (Standard Tier, Input), the cost is approximately $1.75 per million tokens. The Pro variant is significantly more expensive at $21.00 per million input tokens, highlighting its position as a highly specialized tool.
Optimizing Your GPT-5.2 API Usage with Siray.AI
This is where the power of a smart, multi-model API layer becomes indispensable.
- Intelligent Routing: Not every prompt requires the heavy reasoning of GPT-5.2 Pro. Our platform, Siray.AI, automatically routes simple prompts (like quick summaries or translations) to the most cost-effective model (perhaps GPT-5-mini or an efficient open-source alternative) while reserving the GPT-5.2 and GPT-5.2 Pro models for tasks that genuinely require their power. This intelligent orchestration directly minimizes your overall GPT-5.2 API provider costs.
- Performance Guarantee: When you need the power of GPT-5.2, you need it now. Siray.AI guarantees optimal latency and reliable access, ensuring that your production agents operate at peak efficiency without the risk of rate limiting or downtime common when relying on a single vendor.
- Unified Benchmarking: Our platform allows you to run comparative pilots across the different GPT-5.2 Pro vs Thinking benchmarks against models like Gemini 3 Pro, all within a unified testing environment. This ensures you are always using the most cost-efficient and performant model for every single workload—a key advantage for maximizing your ROI.

For developers and enterprises seeking reliable API access for GPT-5.2, Siray.AI provides the necessary performance, failover, and cost controls to move from testing to full production.
The Future of Professional AI is Now
The launch of GPT-5.2 marks a clear turning point in the AI race. It solidifies a shift from consumer-grade novelty to enterprise-grade utility. The focus on reliable agentic execution, expert-level reasoning, and verifiable coding prowess makes it an essential tool for any organization looking to leverage AI for complex, high-value knowledge work.
By providing powerful GPT-5.2 for business automation and superior GPT-5.2 agentic capabilities, this model is ready to redefine productivity.
The core challenge now is not capability, but orchestration and cost management. By using a platform like Siray.AI, your team can deploy GPT-5.2 strategically, ensuring maximum performance and optimal cost efficiency across your entire multi-model architecture.
Ready to experience the new standard in AI reasoning and performance?
You can now test the GPT-5.2 model completely free on Siray.AI. We provide complimentary credits for new users to evaluate its power firsthand, without commitment.