
GPT 5.4: Practical Capabilities and What Developers Should Expect


Introduction
New versions of large language models tend to attract attention because of benchmark numbers or headline capabilities. In practice, however, most engineering teams care about something far more specific: how a model behaves once it is placed inside a real system.
GPT 5.4 appears to move in that direction. Instead of introducing entirely new modalities or dramatic architectural changes, the model focuses on improving reliability across longer prompts, more consistent reasoning, and better adherence to structured instructions.
These changes might sound incremental, but they become meaningful once a model is used in production environments. Systems that rely on structured outputs, tool calls, or chained prompts benefit more from consistency than from occasional bursts of creativity.
This article looks at GPT 5.4 through that practical lens. Rather than focusing only on benchmarks, we will examine where the model fits in the current AI landscape and what developers should realistically expect when integrating it into their applications.
Understanding the Direction of GPT 5.4
The GPT model family has gradually shifted from conversational experimentation toward infrastructure-level capabilities. GPT 5.4 continues that trajectory.
At its core, the model still relies on transformer-based architecture. What appears to have changed is the emphasis placed on training objectives and alignment behavior. GPT 5.4 tends to follow explicit formatting instructions more carefully, and it shows fewer instances where responses drift away from requested structures.
This is particularly noticeable in scenarios where the model is asked to generate code snippets, JSON responses, or configuration templates. Earlier models sometimes introduced extra explanation text or small formatting inconsistencies. GPT 5.4 generally avoids that tendency.
The model also demonstrates stronger behavior when prompts become complex. In workflows that involve multi-step reasoning, GPT 5.4 tends to maintain internal consistency better than earlier iterations.
These improvements may not appear dramatic in simple chat prompts. They become more apparent when the model is used inside automation systems.
Benchmark Performance
Public benchmark tracking sites such as Artificial Analysis show GPT 5.4 performing competitively across reasoning and coding tasks.
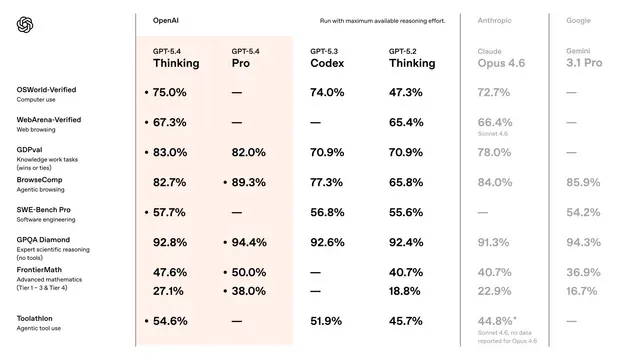
Raw benchmark numbers rarely tell the whole story, but they do provide some context. GPT 5.4 generally demonstrates stronger performance in tasks that require logical consistency across several steps.
Another area where improvements appear is long-context processing. When prompts contain larger documents or extended conversation history, the model retains more relevant details without drifting into unrelated responses.
From a developer perspective, these improvements translate into fewer retries and fewer prompt adjustments. The model tends to respond predictably even when prompts include multiple constraints.
Latency remains within the expected range for a model in this capability tier. While smaller models can produce faster responses, GPT 5.4 offers a balance between reasoning quality and response time that works well for many backend systems.
Positioning Among Current Models
To understand where GPT 5.4 fits, it helps to compare it with a few widely used alternatives such as GPT-4o and Claude Sonnet.
These models are often evaluated in similar application categories, but their design priorities differ.
GPT-4o focuses heavily on multimodal capabilities. It supports image input, voice interaction, and real-time conversation scenarios. For applications that involve multiple media types, GPT-4o remains a strong option.
GPT 5.4, by contrast, leans more toward structured reasoning tasks. Developers building backend tools or AI agents may find that GPT 5.4 behaves more predictably when asked to generate machine-readable responses.
Claude Sonnet offers another interesting comparison point. It is widely recognized for producing clear explanations and well-structured natural language output. In writing-heavy tasks or analytical summaries, Claude models often perform exceptionally well.
GPT 5.4 performs competitively in these areas but places slightly more emphasis on instruction adherence. When prompts contain strict output requirements, the model tends to follow them closely without introducing unnecessary variation.
The differences are subtle but noticeable in production environments.
Real World Use Cases
AI Assistants
Many AI assistants rely on maintaining context across several turns of conversation. GPT 5.4 appears to handle this requirement with fewer coherence issues than earlier models.
In customer support scenarios, for example, the model can track prior information provided by users and maintain logical continuity throughout the interaction. This reduces the need for repeated clarifications.
Developer Tools
Code generation remains one of the most common uses for large language models. GPT 5.4 performs well when asked to generate functions, debug snippets, or explain complex logic.
What stands out during testing is the model’s tendency to follow structural instructions carefully. If a prompt requests a specific programming language or formatting style, GPT 5.4 typically respects that constraint without adding extra commentary.
This behavior is useful in IDE extensions and automated development tools.
AI Agents and Automation Systems
Another growing category involves AI-driven agents capable of performing multi-step tasks. These systems require models that can reason across several operations while producing structured outputs.
GPT 5.4 works well in these environments because its responses are relatively predictable. When integrated into agent pipelines, the model can generate outputs that feed directly into other tools or APIs.
Developers experimenting with agent architectures often evaluate several models before deciding which one fits their workflow. Platforms such as Siray.ai make that process easier by providing unified access to multiple models through a single API interface.
Knowledge Processing
Large organizations frequently deal with extensive internal documentation. GPT 5.4 can assist in summarizing documents, extracting key information, or generating structured reports from long text inputs.
Although it is not positioned primarily as a writing model, its reasoning capabilities make it useful for analytical tasks.
Developer Considerations
Prompt Structure
Like most advanced language models, GPT 5.4 responds best to well-structured prompts. Clear instructions and explicit formatting requirements improve output reliability significantly.
When prompts become ambiguous, the model may revert to more general responses.
Context Size and Latency
Large prompts naturally increase response times. Developers working with long documents should consider splitting tasks into smaller steps when possible.
This approach often improves both performance and accuracy.
Cost and Efficiency
Operational cost remains a critical factor when deploying AI systems at scale. GPT 5.4 sits within the mid-to-high compute tier, meaning cost efficiency depends largely on workload design.
A model that produces reliable outputs on the first attempt can sometimes be more economical than a cheaper model that requires repeated calls.
Siray.ai provides a unified API environment where developers can experiment with GPT 5.4 alongside other models. This makes it easier to evaluate cost and performance tradeoffs without maintaining separate integrations.
Evaluating the Model in Practice
Before deploying GPT 5.4 in production, engineering teams typically conduct several internal tests.
These evaluations often focus on practical metrics such as response reliability, structured output accuracy, and system stability under load.
Running identical prompts across multiple models can reveal subtle differences in behavior. Some models may respond faster, while others demonstrate stronger reasoning.
Unified API platforms like Siray.ai simplify this testing process by allowing developers to switch models without rewriting application logic.
Final Thoughts
GPT 5.4 represents a continuation of the gradual shift toward more reliable and developer-friendly language models.
Its improvements are less about dramatic new capabilities and more about stability. For teams building AI-powered software systems, that stability can make a meaningful difference.
The model performs particularly well in structured workflows, automation pipelines, and development tools where predictable outputs are essential.
Developers interested in experimenting with GPT 5.4 can access it through Siray.ai, which provides unified API access to multiple AI models within a single integration.