
MiMo-V2-Flash Model Review: Performance, Benchmarks, and Use Cases


Introduction
As large language models mature, the market is beginning to separate into clear categories. Some models push the limits of scale and reasoning depth. Others focus on reliability, efficiency, and real-world deployment. Increasingly, teams are looking for models that fall into the second group—models that perform well without introducing unnecessary latency or cost.
The launch of MiMo-V2-Flash fits squarely into this shift.
Developed by Xiaomi’s MiMo team, MiMo-V2-Flash is positioned as a high-speed, low-latency reasoning model, designed for production environments where responsiveness matters just as much as accuracy. Rather than competing directly with heavyweight frontier models, MiMo-V2-Flash focuses on fast inference, efficient token usage, and stable behavior under load.
In this article, we take a closer look at MiMo-V2-Flash—covering its architecture, benchmark performance, strengths and limitations, and the types of applications it is best suited for. We also explain how teams can try and deploy the model easily through siray.ai.
What Is MiMo-V2-Flash?
MiMo-V2-Flash is the latest release in the MiMo model family, with a clear emphasis on speed-first inference. According to the official Hugging Face and GitHub documentation, the model is optimized for:
- Low response latency
- Stable throughput under high concurrency
- Reasoning tasks that do not require extremely long chain-of-thought outputs
This makes it particularly suitable for real-time and near-real-time AI applications, such as interactive tools, assistants, and API-driven workflows.
Unlike general-purpose conversational models, MiMo-V2-Flash is designed to behave predictably, even when called thousands or millions of times per day.
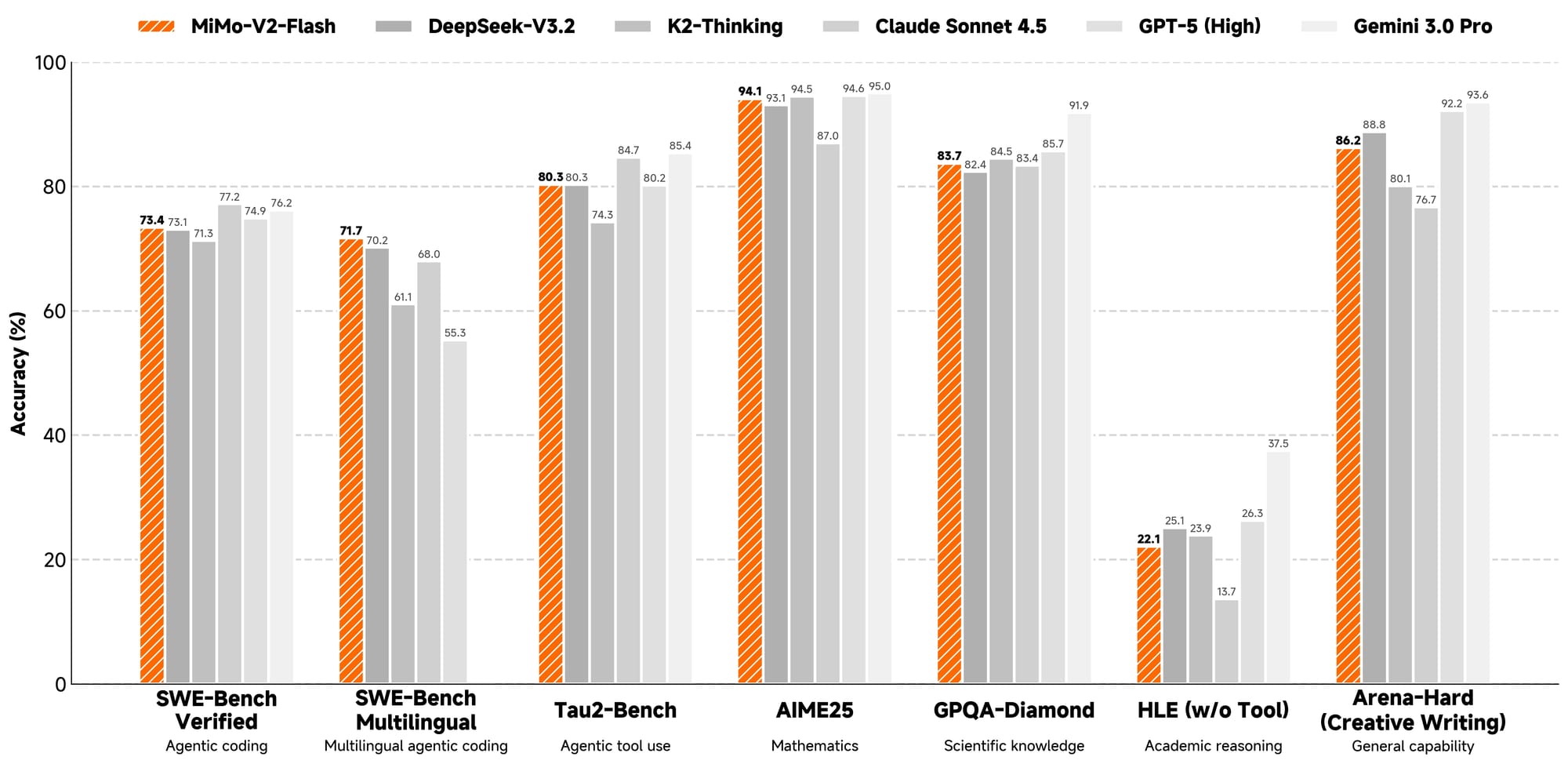
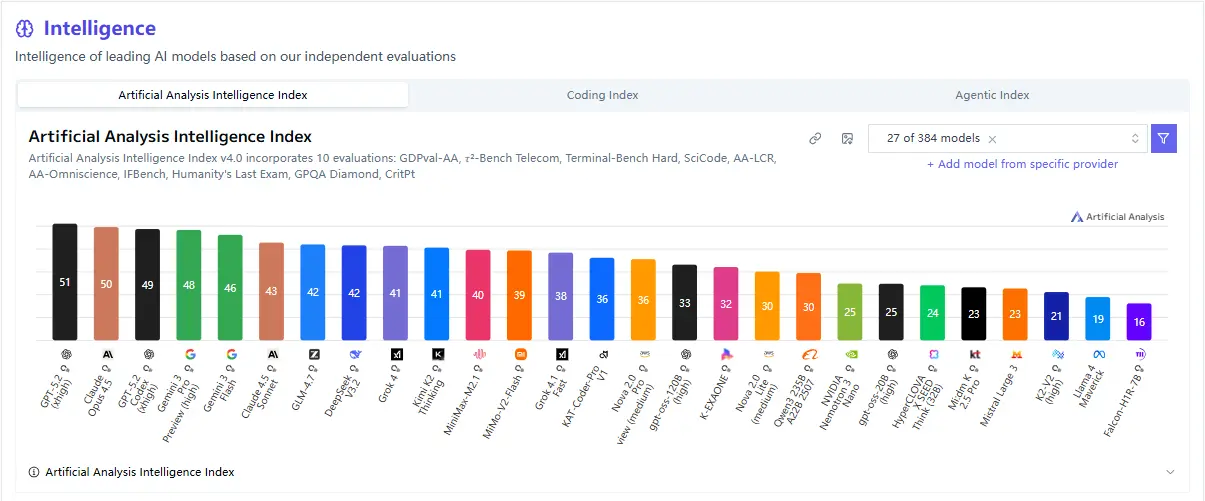
Benchmark Performance Overview
Public benchmark data provides a useful baseline for understanding where MiMo-V2-Flash fits in the broader LLM landscape.
Based on evaluations referenced by ArtificialAnalysis.ai and third-party testing discussed in technical reviews, MiMo-V2-Flash demonstrates a strong balance between reasoning accuracy and inference speed.
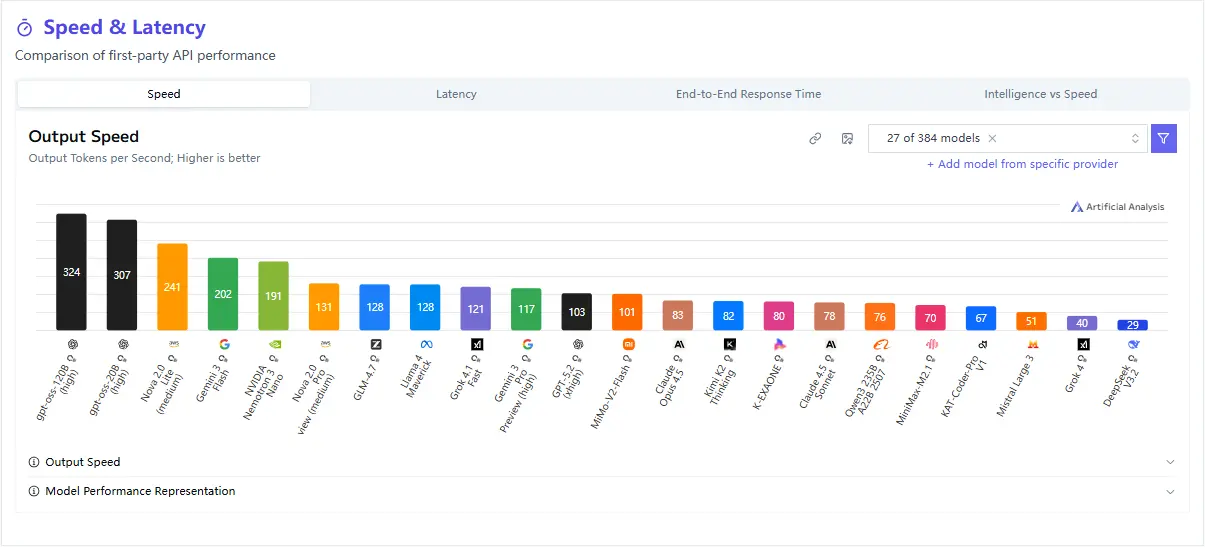
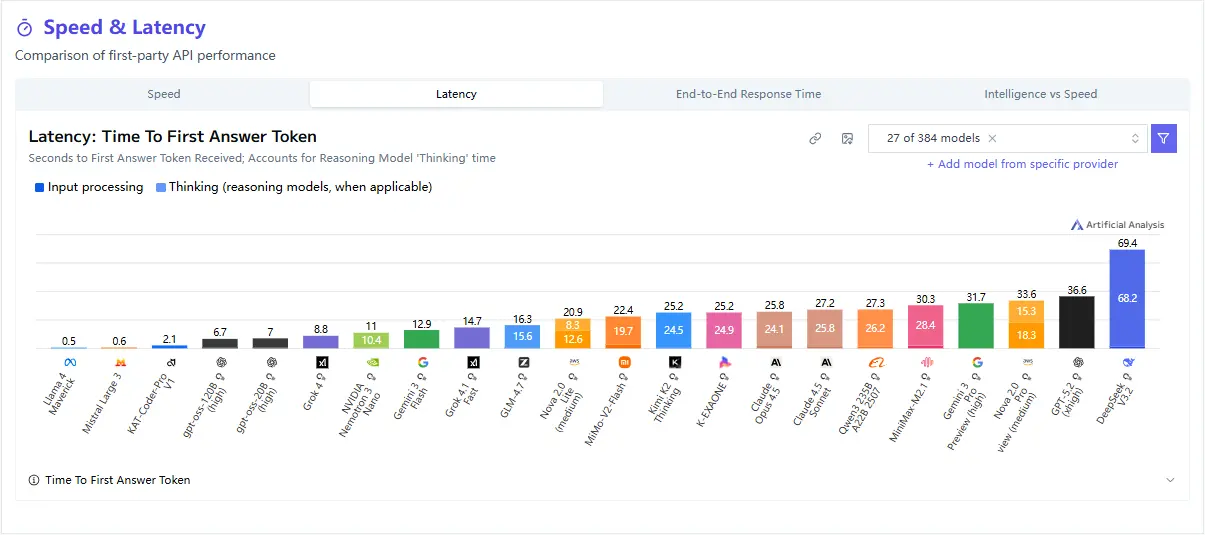
Latency and Throughput
One of the model’s standout characteristics is its low inference latency. Compared to larger reasoning models, MiMo-V2-Flash responds faster and maintains consistent performance under concurrent workloads.
This makes a measurable difference in:
- User-facing applications
- Agent systems
- Streaming or step-by-step reasoning pipelines
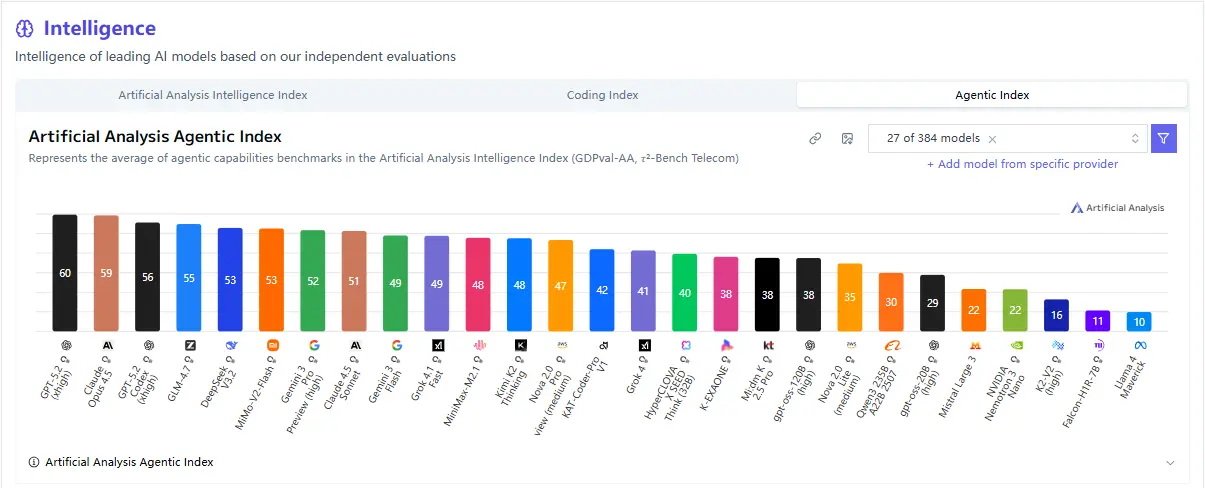
Reasoning and General Intelligence
While MiMo-V2-Flash does not aim to outperform large reasoning-heavy models on deep mathematical benchmarks, it performs competitively on:
- Logical reasoning tasks
- Structured question answering
- Instruction following
For many production use cases, this tradeoff is intentional and practical.
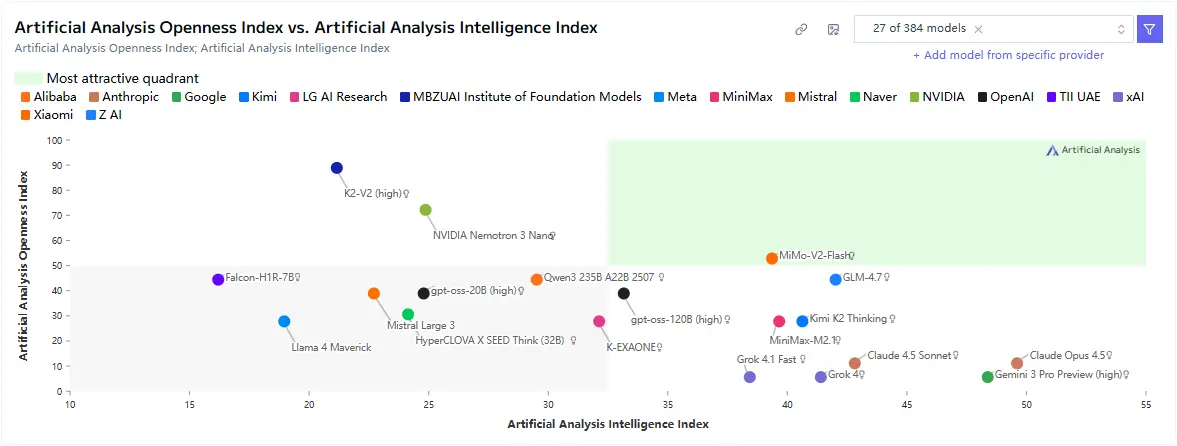
How MiMo-V2-Flash Compares to Other Models
In comparison with heavier reasoning models, MiMo-V2-Flash prioritizes speed and efficiency over maximal depth.
- Compared to deep reasoning models, it produces shorter, more concise outputs.
- Compared to general chat models, it behaves more consistently and predictably.
- Compared to frontier models, it offers significantly lower latency and operational cost.
This positions MiMo-V2-Flash as a strong option for teams that care about response time, scalability, and cost control.
Real-World Use Cases
Real-Time AI Applications
MiMo-V2-Flash is particularly well suited for:
- Interactive AI assistants
- Customer support automation
- Real-time content moderation
- Developer tools and IDE plugins
In these scenarios, response speed often matters more than long, detailed reasoning chains.
RAG and Knowledge Systems
When used in retrieval-augmented generation workflows, MiMo-V2-Flash performs well for:
- Answer synthesis
- Contextual Q&A
- Lightweight reasoning over retrieved documents
Its fast inference allows RAG pipelines to remain responsive even under load.
Enterprise API Workloads
For enterprises running large-scale AI services, MiMo-V2-Flash offers:
- Predictable cost profiles
- Stable performance
- Easier capacity planning
Through siray.ai, teams can integrate MiMo-V2-Flash alongside other models and route requests dynamically based on latency or cost requirements.
Deployment and Access via Siray.AI
Deploying MiMo-V2-Flash through siray.ai simplifies both testing and production rollout.
Siray provides:
- Unified API access to MiMo-V2-Flash and other leading models
- Intelligent routing for cost and performance optimization
- Enterprise-grade stability and monitoring
- Dedicated technical support during integration
This allows teams to evaluate MiMo-V2-Flash in real workloads without committing to a single-model architecture.
Summary
MiMo-V2-Flash represents a clear design choice: fast, reliable, production-ready AI over raw model scale.
- It delivers strong performance for real-time applications
- It keeps latency and cost under control
- It integrates smoothly into modern AI stacks
For teams building AI products where speed, reliability, and scalability matter, MiMo-V2-Flash is a compelling new option—especially when accessed through siray.ai.
You can try MiMo-V2-Flash for free on siray.ai, with unified APIs, cost-optimized routing, and enterprise-level support.