
Mistral Large 3 Review: The New King of Open-Weight Enterprise AI?


Introduction: A New Standard for Open Intelligence
The landscape of open-source artificial intelligence has shifted dramatically over the last 24 months, but December 2025 marks a specific turning point. With the release of Mistral Large 3 (Mistral-Large-2512), the team at Mistral AI has not just iterated on a previous success; they have redefined what "open weights" can achieve in an enterprise environment.
For developers and CTOs alike, the question isn't just "is it good?"—it's "is it efficient enough to replace our proprietary models?"
At Siray.AI, we have been testing the model rigorously since the weights dropped. The headline specifications are staggering: a sparse Mixture-of-Experts (MoE) architecture with 675 billion total parameters (but only 41 billion active during inference), a massive 256k context window, and native multimodal capabilities.
But specs are just numbers until they solve a problem. In this deep dive, we will explore why Mistral Large 3 is poised to be the default engine for complex reasoning, coding agents, and multilingual applications in 2026—and how you can test it immediately on our platform.

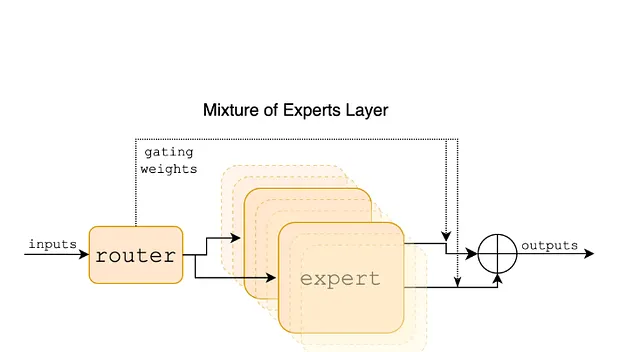
The Architecture: Smart Scale with Mixture-of-Experts
To understand why Mistral Large 3 performs so well, you have to look under the hood. The challenge with Large Language Models (LLMs) has always been the trade-off between intelligence (which usually requires massive parameter counts) and inference cost (latency and compute price).
Mistral Large 3 utilizes a highly refined Sparse Mixture-of-Experts (MoE) architecture.
- Total Parameters: ~675 Billion
- Active Parameters: ~41 Billion
Think of this like a massive library with 675 billion books, but for any specific question, the librarian only references the 41 billion most relevant ones. This allows the model to store an immense amount of "world knowledge" and nuance—essential for enterprise use cases—while maintaining the inference speed and cost profile of a much smaller model.
This is a critical advantage for users on Siray.AI. It means you get frontier-class reasoning without the latency usually associated with models approaching the trillion-parameter mark. Whether you are running complex financial analysis or real-time customer support bots, the efficiency gains here are tangible.
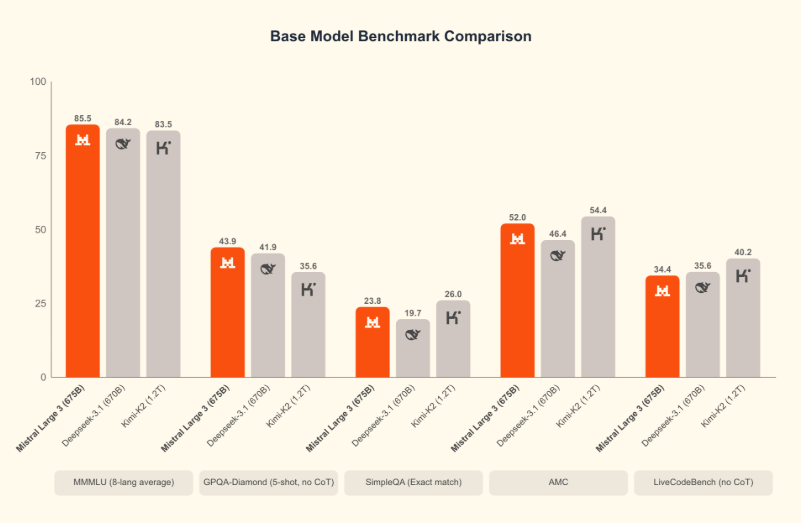
Benchmarks: How Does It Stack Up?
We know that in the AI world, claims are cheap and benchmarks are the currency of trust. We leveraged data from independent sources like Artificial Analysis and our own internal testing to see where Mistral Large 3 lands.
The results place it firmly at the top of the open-weight leaderboard, trading blows with proprietary giants.
1. General Reasoning & Knowledge In standard benchmarks like MMLU-Pro and GPQA Diamond (which tests graduate-level reasoning), Mistral Large 3 shows significant improvements over its predecessor, Mistral Large 2. It specifically excels in "nuanced" tasks where context and subtlety matter.
2. The Coding & Agentic Edge This is where the model shines. In benchmarks like SWE-bench (software engineering tasks) and HumanEval, Mistral Large 3 outperforms key competitors like DeepSeek V3.1 and Kimi K2 in specific multilingual coding tasks. The model demonstrates a superior ability to follow complex, multi-step instructions without losing the thread—a common failure point for previous open models.
3. Multilingual Superiority True to its European roots, Mistral AI has ensured this model is not just English-centric. It handles French, German, Spanish, Italian, and notably, Arabic and Asian languages, with native-level fluency. For global enterprises using Siray.AI to deploy cross-border customer service agents, this eliminates the need for separate models for separate regions.
Deep Dive: Key Features for 2026 Workflows
Beyond raw scores, Mistral Large 3 introduces utility features that make it a production-ready powerhouse.
1. The 256k Context Window
"Needle in a haystack" retrieval is no longer a luxury; it's a requirement. Mistral Large 3 supports a 256,000 token context window. To put that in perspective, that is roughly 300-400 pages of dense technical documentation or an entire codebase repository processed in a single prompt.
This capability is vital for RAG (Retrieval-Augmented Generation) applications. You can feed the model entire quarterly reports, legal contracts, or technical manuals, and ask it to synthesize connections across the entire dataset.
2. Native Multimodal Capabilities
Mistral Large 3 isn't just text-in, text-out. It features a built-in vision encoder. This allows the model to analyze charts, read complex invoices, and interpret screenshots natively.
If you are building an expense management tool on Siray.AI, for example, you can now pass images of receipts directly to the model. It will extract the data (OCR), categorize the expense, and flag anomalies in one pass, without needing a separate OCR tool like Tesseract.
3. Function Calling and JSON Mode
For developers building agents, reliability is key. Mistral Large 3 has been fine-tuned for "Agentic" workflows. It adheres strictly to JSON schemas and utilizes function calling with high accuracy. This reduces the "hallucination" rate when the model interacts with external APIs—a critical feature for anyone building automated banking or booking systems.
The Enterprise Argument: Why Open Weights Matter
As we move deeper into the AI era, the debate between "Open" and "Closed" AI is settling. For enterprise, Open Weights (like Mistral Large 3) offer three distinct advantages:
- Data Sovereignty: You are not sending your sensitive customer data to a "black box" API owned by a competitor. You can host Mistral Large 3 within your own VPC or on a trusted private cloud partner.
- Fine-Tuning: Because the weights are available (Apache 2.0 license), you can fine-tune the model on your proprietary data. A law firm can take Mistral Large 3 and train it further on 50 years of case files to create a specialized legal assistant that no generic model can match.
- Cost Control: With optimized inference (especially utilizing FP8 quantization on NVIDIA H200s), the cost-per-token for self-hosted models effectively drops as scale increases, unlike API-based pricing which scales linearly.
At Siray.AI, we specialize in bridging this gap. We provide the infrastructure to run these open-weight models securely, giving you the control of self-hosting with the ease of a managed service.
Use Case Spotlight: The "Cold Start" Marketing Engine
Let’s apply this to a real-world scenario relevant to growth teams. Imagine you are launching a new SaaS product and need to generate a "Cold Start" marketing campaign.
Using Mistral Large 3 on Siray.AI, you could execute the following workflow in minutes:
- Context Loading: Upload your entire product whitepaper and competitor analysis PDFs (utilizing the 256k context).
- Visual Analysis: Upload screenshots of your competitor’s landing pages. Ask the model to analyze their UX and value proposition claims visually.
- Strategy Generation: Ask the model to generate 10 unique "Growth Hack" strategies based on the Product-Led Growth methodology, specifically tailored to the gaps found in the competitor analysis.
- Content Creation: Have the model output blog posts, email sequences, and social captions in 5 different languages for your global launch.
The result is a cohesive, data-backed marketing strategy generated in a fraction of the time it would take a human team to collate the data.
How to Access Mistral Large 3
While you can download the 675B parameter model from Hugging Face, deploying it requires significant hardware. You would need a cluster of NVIDIA H100s or the newer H200s to run it efficiently at reasonable latency. For most companies, the hardware investment alone is a massive barrier to entry.
Hugging Face Download URL: https://huggingface.co/mistralai/Mistral-Large-3-675B-Instruct-2512
There is a better way.
We have already optimized Mistral Large 3 on our high-performance clusters. You don't need to configure Docker containers, manage CUDA drivers, or worry about GPU availability.
Summary: The Verdict
Mistral Large 3 is not just an incremental update; it is a statement that open-weight AI is ready for the most demanding enterprise workloads. With its massive parameter count efficiently managed by MoE architecture, superior coding skills, and robust multimodal capabilities, it offers a compelling alternative to closed ecosystems.
Whether you are looking to build the next generation of coding agents, automate complex document analysis, or simply reduce your reliance on expensive proprietary APIs, Mistral Large 3 demands your attention.
The barrier to entry has never been lower. You don't need a data center to test the power of 675 billion parameters. You just need a Siray.AI account.
Ready to experience the power of Mistral Large 3?