
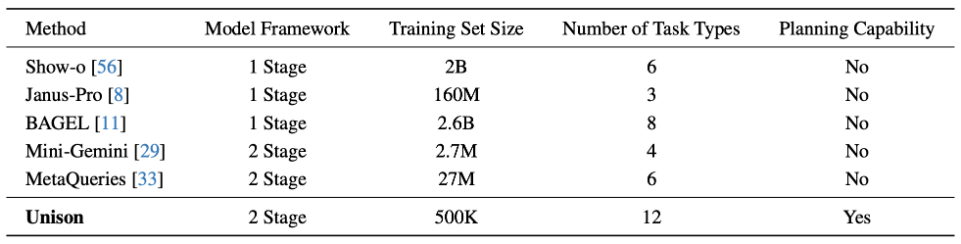
Unison: Unifying AI Understanding and Generation Tasks


The Current Problem: Fragmentation in AI
Let's be real: the AI world right now is a mess of mismatched puzzle pieces. "Multimodal" gets thrown around like confetti, but try actually using it. Want to break down a video? Fire up a vision-language model (VLM). Need to whip up an image? Swap over to a diffusion model. And if you're tweaking that image with some finicky instructions? Good luck—grab a third tool and pray it plays nice. It's exhausting.
For developers and researchers, this fragmentation creates a massive headache:
- Workflow Friction: Humans are forced to be the "middleware," manually passing prompts and data between different models.
- High Costs: Building one mega-model to rule them all will take thousands of GPU hours and budgets that could fund a small startup.
- Lack of Automation: Most systems cannot automatically detect if a user wants to analyze content or create it—they need to be explicitly told which mode to use.
What is Unison?
Picture this: a two-stage setup that's dead simple, runs on a shoestring, and handles everything from video breakdowns to wild image edits—automatically, no hand-holding required. Born from a collab between folks at The University of Hong Kong, Tongyi Lab, and Fudan University, Unison mashes up understanding (those clever VLMs) with generation (diffusion pros) to tackle 12 different tasks across text, images, and videos.
The kicker? It does all this with just 500,000 training samples and 50 GPU hours. In a field obsessed with trillion-parameter behemoths, that's like showing up to a drag race on a bicycle—and winning.
The most groundbreaking part? It achieves this with minimal resources: only 500k training samples and 50 GPU hours.
The Unison Solution: A "Brain" and a "Painter" Working in Sync
At its core, Unison feels less like rocket science and more like a well-oiled team: one thinks, the other creates, and they sync without a hitch.
Stage 1: The Understanding Model (The "Brain")
This is your sharp-eyed analyst, built on a fine-tuned Qwen2.5-VL-3B-Instruct (using efficient LoRA tweaks). It gobbles up any input—text rants, static pics, or rambling videos—and doesn't just stare blankly. No, it reads your mind (sort of):
- Spot a question like "What's the vibe in this clip?" It dives in and spits out a spot-on answer.
- Catch something creative, like "Turn the cat in this photo into a cyberpunk graffiti masterpiece"? It tags the task (style transfer, say), pulls out key details (colors, mood, resolution), and hands off crystal-clear marching orders.
No more guesswork—it's all automatic intention parsing, down to nitty-gritty meta-info like video length or image size.
Stage 2: The Generation Model (The "Painter")
Enter the artist: Wan2.1-VACE-1.3B, a powerhouse for churning out crisp visuals. It takes the brain's blueprint and paints it to life—be it a neon cityscape from scratch or a seamless edit erasing that awkward photobomber.
The secret sauce? A featherweight projector module that bridges the gap. It's a tiny, trainable go-between that translates the brain's high-level chatter into pixel-perfect signals for the painter. No clunky adapters, just smooth, low-cost alignment.
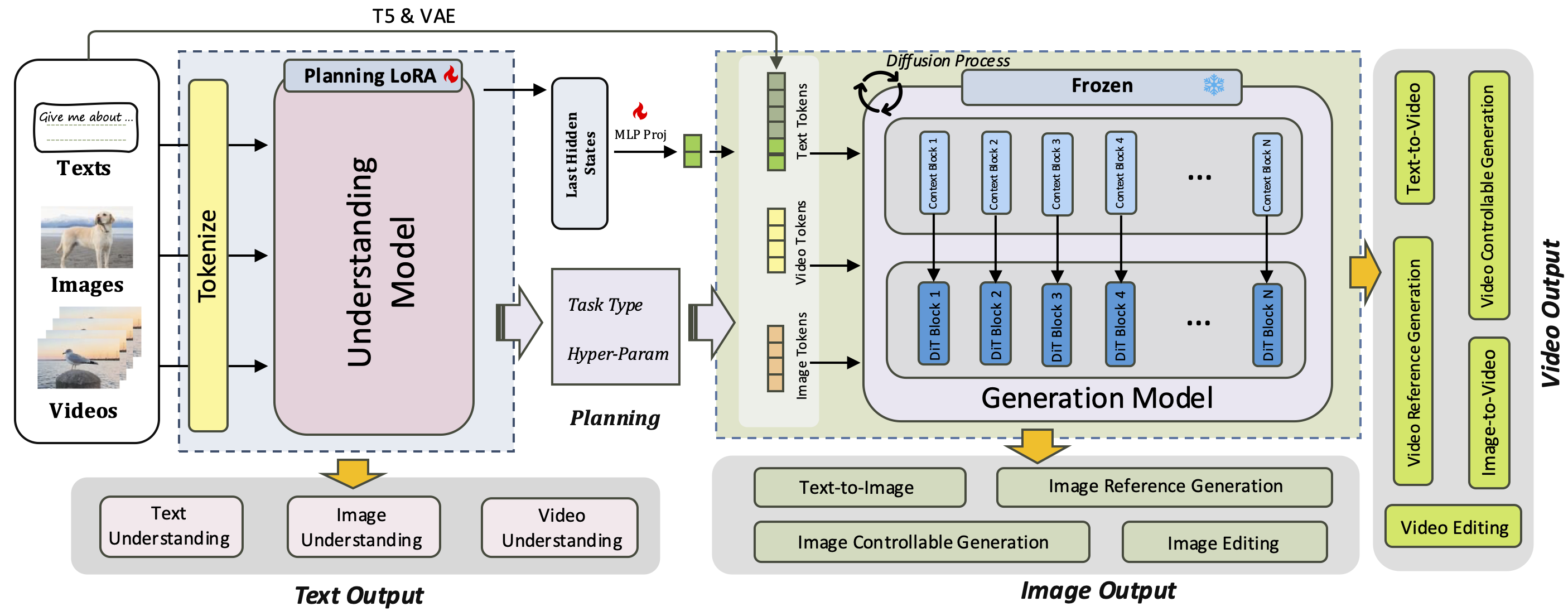
One Framework, a Dozen Tricks Up Its Sleeve
This brain-painter duo isn't picky—it flexes across 12 tasks like it's no big deal, blending understanding and generation into one seamless flow. Here's the lineup:
Understanding Side (Making Sense of the Chaos):
- Text QA: Grill it on articles or docs—"What's the main argument here?"
- Image Captioning: "Paint me a word picture of this sunset hike."
- General VQA: "How many red cars in this street scene?"
- Video Analysis: "Break down the plot twists in this trailer."
Generation Side (Bringing Ideas to Life):
5. Text-to-Image/Video: "Dream up a steampunk library at midnight."
6. Visual Editing: "Swap the sky for a starry nebula—keep the foreground intact."
7. Controllable Generation: Drop in a sketch or mask to steer the output.
8. IP/Reference Generation: "Remix this superhero pose into a rainy alley fight."
(And that's just eight—the other four slot into hybrids like video captioning or masked edits, all under the hood.)
It's versatile without the bloat, preserving the punch of those pre-trained heavy-hitters while adding that effortless automation.

Why This Matters for the Future of AI
In a world where Big Tech torches fortunes on ever-bigger models, Unison whispers a radical truth: smarts > size. By piggybacking on proven foundations like Qwen and Wan, and stitching them with clever, cheap tweaks, it flings open the doors to multimodal magic for the rest of us—not just the GPU overlords.
Imagine chatting with an AI that watches your favorite flick, debates the ending with you, then—bam—spits out a custom poster in your style. No app-switching, no tutorials, just pure flow. That's not hype; that's the future Unison is sketching right now. If you're tinkering with AI workflows, this one's worth a deep dive.