
Z-Image Turbo Review: Best Free Text-to-Image AI Generator


The landscape of generative AI is shifting rapidly. For the past year, the conversation has been dominated by massive, heavy models. While they produce stunning results, they often come with a significant tax: they are slow, computationally expensive, and notoriously bad at following complex instructions—especially when it comes to rendering text. If you have ever tried to generate a simple coffee shop sign or a bilingual marketing poster, you know the frustration of seeing "gibberish" where clear letters should be.
Enter Z-Image, a groundbreaking new model developed by Tongyi-MAI that is poised to redefine efficiency in the generative space. It doesn't just iterate on existing technology; it fundamentally restructures how AI perceives and generates visuals.
At Siray.AI, we are committed to bringing you the bleeding edge of AI capability. We are thrilled to announce that the Z-Image model family is now integrated into our platform. Whether you are a developer looking for low-latency APIs or a designer needing precise text rendering, Z-Image offers a compelling new solution.
In this deep dive, we will explore the revolutionary architecture behind Z-Image, analyze its performance against industry heavyweights, and show you how to leverage its unique bilingual capabilities directly on Siray.AI.
The Architecture Shift: What is Scalable Single-Stream DiT?
To understand why Z-Image is different, we have to look "under the hood." Most traditional image generation models, including Stable Diffusion XL (SDXL) and FLUX, utilize what is known as a dual-stream architecture. In these systems, text prompts and visual data are processed through separate pathways that only communicate occasionally. While effective, this separation can lead to a "disconnect" where the model fails to fully grasp the semantic nuance of your prompt.
Z-Image introduces the Scalable Single-Stream Diffusion Transformer (S3-DiT).
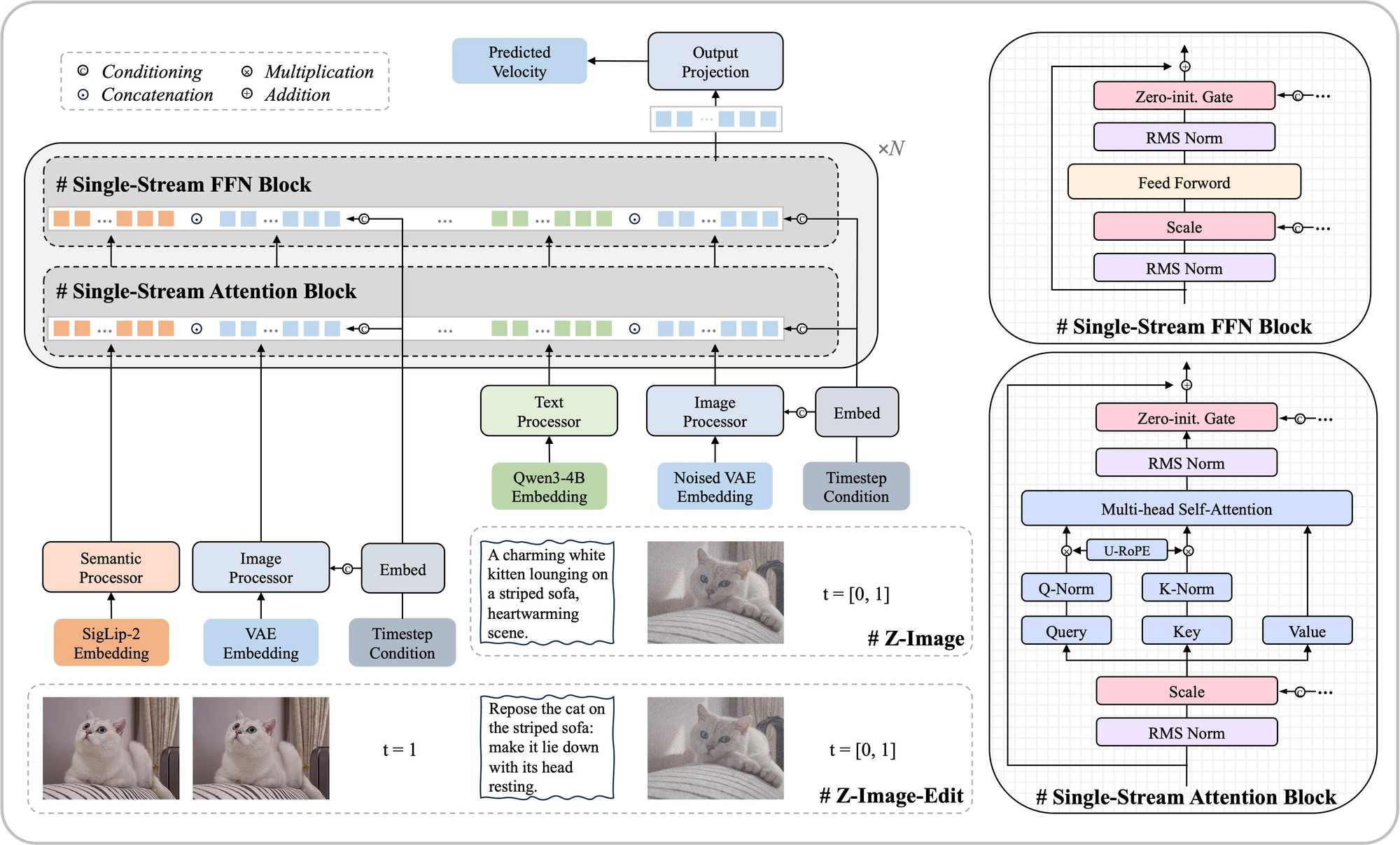
In this architecture, the barriers are removed. Text tokens, visual semantic tokens, and image VAE (Variational Autoencoder) tokens are concatenated into a single, unified sequence. They flow through the transformer together. This means the model processes your text instructions and the developing image simultaneously, at every single step of the generation process.
Why does this matter?
- Parameter Efficiency: By unifying the streams, Z-Image achieves incredible results with only 6 billion parameters. This makes it significantly lighter than many of its competitors while maintaining—and often exceeding—their visual fidelity.
- Deep Semantic Understanding: Because the text and image data are "speaking the same language" throughout the entire process, Z-Image adheres to prompts with startling accuracy. It doesn't just "paste" elements together; it understands the relationship between them.
Z-Image-Turbo: Speed Without Compromise
The flagship variant currently making waves is Z-Image-Turbo. In the world of AI, "Turbo" often implies a drop in quality for the sake of speed. However, Z-Image-Turbo breaks this stereotype using a technique called Decoupled-DMD (Distribution Matching Distillation).
This distillation process allows the model to generate high-fidelity, photorealistic images in just 8 Number of Function Evaluations (NFEs).
Let’s put that into perspective. Traditional diffusion models might require 20, 30, or even 50 steps to produce a usable image. Z-Image-Turbo does it in 8. On enterprise-grade hardware like the H800, this translates to sub-second inference latency. Even on consumer-grade GPUs with 16GB of VRAM, the performance is blistering.
For users on Siray.AI, this means near-instant feedback. You can iterate on designs, test prompt variations, and refine your workflow without the agonizing 30-second wait times typical of older models.
The Killer Feature: Bilingual Text Rendering
If there is one "holy grail" in AI image generation, it is legible text. Until now, generating a coherent sentence on a billboard or a logo within an image was a roll of the dice.
Z-Image changes the game with robust Bilingual Text Rendering.
Unlike many Western-centric models that struggle with anything beyond simple English nouns, Z-Image has been trained to master both English and Chinese text.
- For English: It handles complex sentences, font styles, and integration into the scene with high consistency.
- For Chinese: It is one of the few open-weight models capable of rendering accurate Chinese characters (Hanzi) without hallucinating incorrect strokes.
Use Case Spotlight: Imagine you are a marketing manager creating assets for a global campaign. You need a poster of a futuristic city with a neon sign that says "Welcome" in English and "欢迎" in Chinese.
- With previous models: You would generate the image, then open Photoshop to manually overlay the text because the AI would output alien symbols.
- With Z-Image on Siray.AI: You simply prompt: "A cyberpunk street scene with a neon sign glowing 'Welcome' and '欢迎'." The model renders both scripts accurately, with the correct lighting, perspective, and texture applied to the letters.
This capability alone makes Z-Image an indispensable tool for e-commerce, advertising, and cross-border content creation.

Benchmarking Z-Image: How Does It Stack Up?
We know that claims of "speed" and "quality" need data to back them up. Let’s look at the benchmarks, referencing data from the Alibaba AI Arena and other independent analyses.
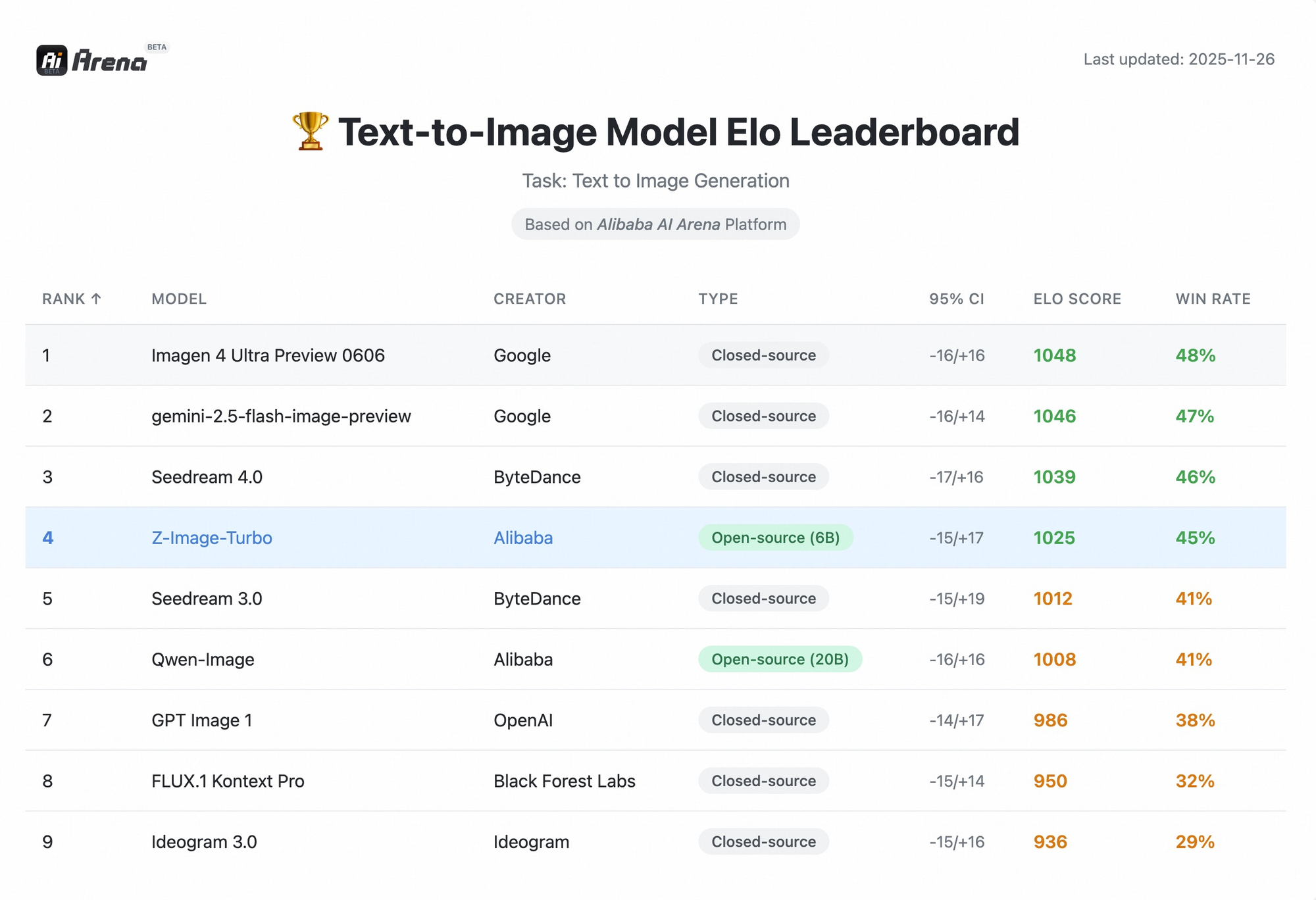
1. Visual Fidelity (Elo Rating) In blind A/B testing (Elo-based Human Preference Evaluation), Z-Image-Turbo has shown highly competitive performance. It rivals much larger, closed-source models. When compared to FLUX.1 Kontext Pro(another fast model), users frequently rate Z-Image higher for prompt adherence and text accuracy, even though Z-Image operates with a leaner parameter count (6B).
2. Inference Speed According to benchmarks from ArtificialAnalysis.ai and internal testing:
- Standard Diffusion (SDXL): ~30-50 steps for high quality.
- Z-Image-Turbo: 8 steps fixed. In a real-world API environment, this results in a throughput increase of nearly 300-400% compared to standard non-distilled models.
3. Resource Consumption The 6B parameter size is a "Goldilocks" zone. It is large enough to contain deep world knowledge and stylistic versatility, but small enough to run on a single robust consumer GPU (like an RTX 3090 or 4090) or strictly optimized cloud instances. This efficiency passes cost savings directly to the user.
Model Comparison: Z-Image vs. The Rest
| Feature | Z-Image (Turbo) | FLUX.1 (Schnell) | SDXL Turbo |
| Architecture | Single-Stream DiT | DiT + MM-DiT | U-Net |
| Parameters | 6 Billion | 12 Billion | ~2.6 Billion (Active) |
| Steps required | 8 | 4-8 | 1-4 |
| Text Capability | Excellent (Eng + Chi) | Good (Eng) | Weak |
| Photorealism | High | Very High | Medium/High |
| License | Apache 2.0 (Open) | Apache 2.0 | Commercial Restrictions |
Use Cases: Who Should Use Z-Image?
We have integrated Z-Image into Siray.AI because we believe it solves specific problems for our diverse user base.
1. E-Commerce & Mockups Create realistic product packaging that includes specific brand names. If you are launching a coffee brand, you can generate the bag sitting on a cafe table with your brand name perfectly written on the label.
2. Social Media Content Speed is key for social media managers. With sub-second generation, you can react to trends instantly. Create memes, reaction images, or event announcements in seconds.
3. Global Marketing As mentioned, the Chinese/English capability allows for the creation of localized assets without the need for a translator or a graphic designer to manually edit the image.
4. Storyboarding & Ideation For creative directors, the ability to generate "good enough" high-fidelity images in under a second allows for real-time brainstorming sessions where the AI keeps up with the conversation.

How to Use Z-Image on Siray.AI
We have made accessing Z-Image incredibly simple. You don't need to worry about VRAM, CUDA drivers, or Python environments.
- Log in to Siray.AI: Navigate to the "Image Generation" dashboard.
- Select the Model: Choose "Z-Image Turbo" from the model dropdown menu.
- Enter Your Prompt: Be descriptive! Remember, the Single-Stream architecture loves detail.
- Example: "A cinematic shot of a vintage robot painting a canvas, detailed texture, 8k resolution, the canvas says 'HELLO WORLD' in red paint."
- Hit Generate: Experience the speed yourself.
Z-Image represents a maturity in the AI industry. We are moving past the phase of "bigger is always better" and entering an era of "smarter and faster." By utilizing the Single-Stream DiT architecture and advanced distillation techniques, Tongyi-MAI has delivered a model that punches well above its weight class.
To recap, Z-Image delivers:
- State-of-the-art Photorealism at 6B parameters.
- Unmatched Bilingual Text Rendering (English & Chinese).
- Lightning Fast Inference (8 steps).
- Open Availability for the community.
Whether you are a developer integrating API endpoints or an artist exploring new tools, Z-Image is a necessary addition to your toolkit.
Sign up today and experience the speed of the next generation of AI.